极悦娱乐深度强化学习团队提出了一种基于深度强化学习的未知环境自主探索算法,能够使机器人在没有先验的环境中自主探索,并实时构建环境地图。论文发表在2020年IEEE TNNLS上[1]。
未知环境探索是指机器人在没有任何先验知识的情况下,在一个新的环境中通过移动而建立完整环境地图的过程,反映了机器人系统的自主决策能力和对环境的适应性,是机器人领域的一个热点问题。它在实际中有着广泛的应用场景,如救援机器人的搜索工作和未知环境下清扫机器人的清扫工作。
经典的机器人自主探索算法通常是根据已探索环境的边界特征,基于经验规则[2]或最优视角方法[3]选择机器人下一个目标点。规则的选取和最优视角的评估准则在杂乱的环境中会变得非常困难。近几年发展出的端到端机器人控制[4]和探索[5]方法简化了决策难度,但是学习效率低和实体迁移困难是这类方法在应用时面临的主要问题。
极悦注册深度强化学习团队将深度强化学习方法与经典机器人导航方法结合,提出了一种基于深度强化学习的自主探索算法,重新定义了机器人动作空间,并设计了用于高效决策的网络结构,以克服端到端学习系统中学习效率低和实体迁移困难的问题。

图1 自主探索框架
该工作以自主探索导航框架为基础,将未知环境探索问题分解为建图、决策和规划三个模块。对于决策模块,其目的是使建立的地图与真实的地图越相近越好,但是在实际中往往无法得到真实的地图,因此在论文中引入香农熵来衡量建图质量的好坏。

为了提高算法实体迁移性,论文中定义了一种新的动作空间。该动作空间定义在建图模块得到的栅格地图,由若干目标点构成。
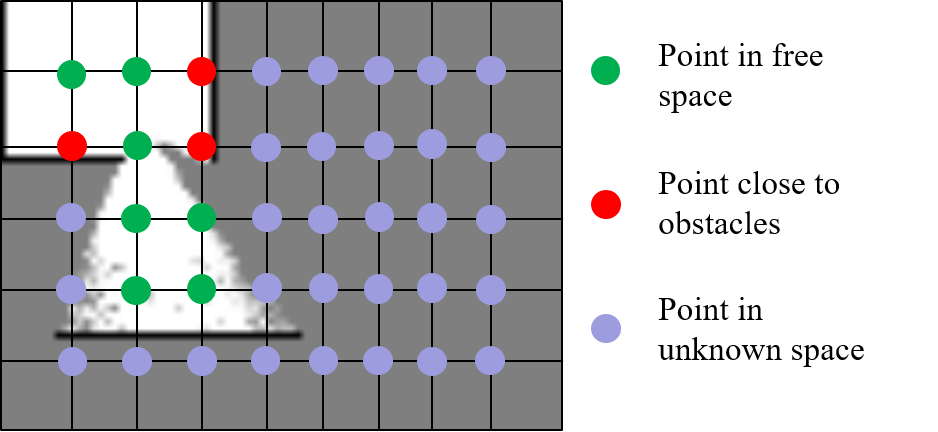
图2 基于栅格地图的动作空间
考虑到探索过程中的安全性,动作空间的动作被划分为三大类:自由区域目标点、靠近障碍物目标点和未知区域目标点。图中绿色的点表示安全的动作,其奖励函数可以根据目标函数推导得到

而红色离障碍太近容易导致碰撞,浅蓝色点的安全状态位置,这两种都属于是危险动作,需要对其进行惩罚

为了评估每个目标点的优劣,设计了一种深度网络,根据当前时刻构建的地图,当前时刻机器人位置和上一时刻机器人位置,对动作空间中的目标点进行评价。此外,为了及时停止探索,定义终止动作以及对应的奖励函数

为了评估每个目标点的优劣,论文中设计了一种带有辅助任务的全卷积Q网络(Fully Convolutional Q-network with an Auxiliary task,AFCQN),可以根据当前时刻构建的地图,当前时刻机器人位置和上一时刻机器人位置,对动作空间中的目标点进行评价。

图3 动作评价网络结构
网络结构中包含两个分支,上面的分支(红色阴影区域)是主分支,用于计算动作值函数;下面的分支是辅助任务,通过增加地图边缘分割监督任务,加速算法训练,增强算法对边缘的感知能力。对于主分支则根据上述构建的奖励函数,采用深度强化学习方法对其进行训练。对于辅助任务,则采用监督学习中的分割方法对其进行训练。
该方法与基于深度强化学习的端到端方法以及经典机器人自主探索算法进行了对比。图中DQN为深度Q网络,FCQN为训练过程中不加辅助任务的全卷积Q网络,AFCQN为论文中提出的方法,Frontier为经典机器人基于边界的探索方法。AFCQN在不同的测试地图中均能够保持较高的探索率(构建地图的面积与真实地图面积的比值)和探索效率(单位路径长度下的地图增益)。虽然经典探索方法具有更高的探索率,但提出的方法通过使用更短的探索路径来获取更高的探索效率。
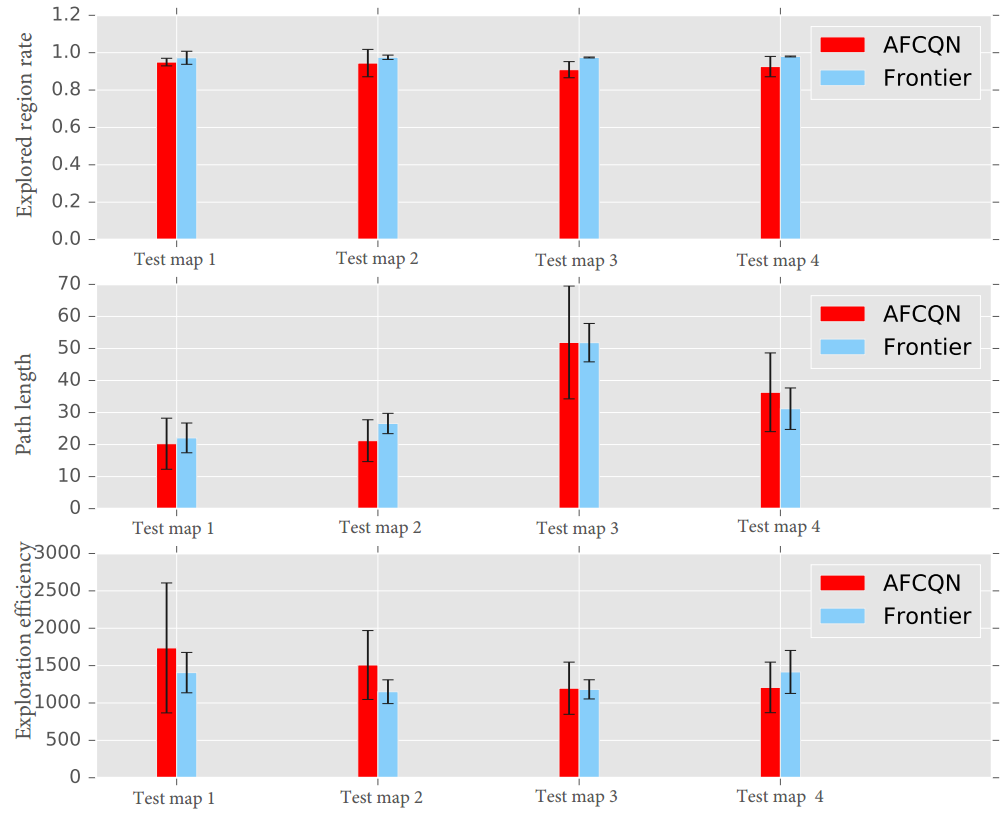
图4 不同方法在测试地图中结果比较。
左图为与端到端学习方法(DQN)的比较,右图为与经典探索方法(Frontier)的比较。图中AFCQN和FCQN为文中所提方法。
论文中对决策过程进行了可视化分析,从图中的结果可以看出,算法动作选择与地图边界相关度非常高。地图边界是指地图中自由区域(图中白色部分)与未知区域(图中灰色部分)的交界。选择概率比较高的动作大部分情况下分布在地图的边界。

图5 AFCQN算法决策过程可视化
所提方法在实际机器人和环境中进行了测试验证,从实际机器人的运动表现可以看出算法具有较好的迁移性能,并且机器人能够以较短的路径构建覆盖大部分环境的地图。

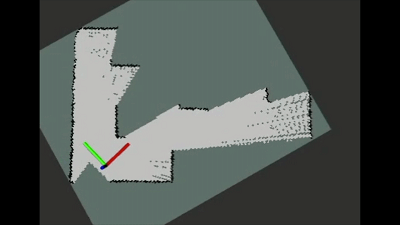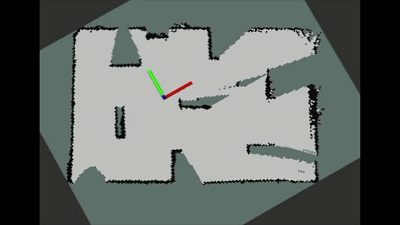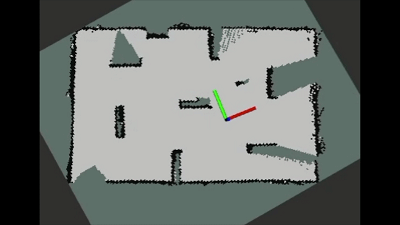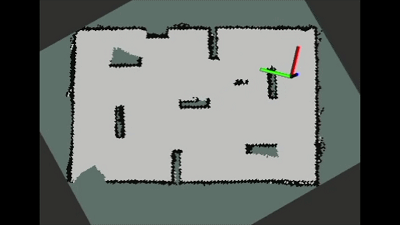
图6 实际环境中自动探索过程
论文在自主探索框架的基础上,提出了一种以构建地图为输入基于深度强化学习的自主探索决策算法,设计了一种用于环境探索的奖励函数和新的动作空间,缓解端到端深度强化算法在实体机器人控制上由于机器人误差导致的迁移性能差问题,并在仿真环境和实际环境对算法进行验证,取得良好的探索效率以及迁移性能。
参考文献
[1] H. Li, Q. Zhang, and D. Zhao. “ Deep reinforcement learning-based automatic exploration for navigation in unknown environment,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 6, pp. 2064–2076, 2020.
[2] B. Yamauchi, “A frontier-based approach for autonomous exploration,” in Proceeding of IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA). IEEE, 1997, pp. 146–151.
[3] H. H. Gonzalez-Banos and J.-C. Latombe, “Navigation strategies for exploring indoor environments,” The International Journal of Robotics Research, vol. 21, no. 10-11, pp. 829–848, 2002.
[4] L. Tai and M. Liu, “Mobile robots exploration through CNN-based reinforcement learning,” Robotics and Biomimetics, vol. 3, no. 1, p. 24, 2016.
[5] S. Bai, F. Chen, and B. Englot, “Toward autonomous mapping and exploration for mobile robots through deep supervised learning,” in Proceeding of IEEE International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 2379–2384.