NeurIPS全称神经信息处理系统大会(Conference on Neural Information Processing Systems),是机器学习和计算神经科学领域的顶级国际会议。NeurIPS 2024将于今年12月9日至15日在加拿大温哥华召开。
1.MetaLA:对Softmax注意力图的统一最优线性逼近 * Oral
MetaLA: Unified Optimal Linear Approximation to Softmax Attention Map
论文作者:侴雨宏,姚满,王可心,潘昱锜,朱芮捷,吴冀彬,钟怡然,乔宇,徐波,李国齐
研究介绍:
Transformer架构以及自注意力机制显著提升了大模型性能,但却引入了随序列长度的二次方计算复杂度。各种线性复杂度模型,如线性Transformer(LinFormer),状态空间模型(SSM)和线性RNN(LinRNN)等,被提出作为自注意力的高效替代。在本工作中,我们首先在形式上统一了目前所有的线性模型,并总结了其自特点。接着,提出了最优线性注意力设计的三个必要条件:动态记忆能力;静态逼近能力;最少参数近似。本文发现目前的所有线性复杂度大模型都不能满足所有的三个必要条件,导致性能次优。进而本文提出了MetaLA模型,能够满足上述最佳逼近必要条件,并在检索任务、语言建模、图像分类和长序列建模等实验上,本文验证了MetaLA的有效性。

线性模型的统一形式(并行和循环两种形式)
02.DuQuant:通过对偶变换分散LLM的离群值,打造更强大的量化大型语言模型 * Oral
DuQuant: Distributing Outliers via Dual Transformation Makes Stronger Quantized LLMs
论文作者:林浩坤,徐浩博,吴一尘,崔景植,张英韬,牟林湛,宋林琦,孙哲南,魏颖
研究介绍:
当今LLM中存在非常大的激活值(outliers),为低比特量化带来了巨大挑战,我们在实验中发现LLM FFN模块中的down_proj layer存在明显的massive outliers,表现为大于几百的异常值并局限于个别的tokens中,这些massvie outliers造成SmoothQuant和OmniQuant等算法在4bit权重激活量化中表现糟糕。为了更好消除massive outliers和normal outliers,DuQuant通过学习旋转矩阵和平移变换矩阵,在激活矩阵(Activation)内部将outliers转移到其他通道,最终得到平滑的激活矩阵,从而大幅度降低了量化难度。旋转矩阵和平移变换矩阵都是正交矩阵,保证了权重激活输出(XW)的不变性,我们还通过严谨的理论推导了证明了两种变换有效降低了量化误差。DuQuant在4-bit权重激活量化setting下达到了SOTA的效果,我们验证了LLaMA、Vicuna、Mistral系列模型,在PPL、QA、MMLU和MT-Bench等任务上DuQuant都明显提升了量化模型的性能。
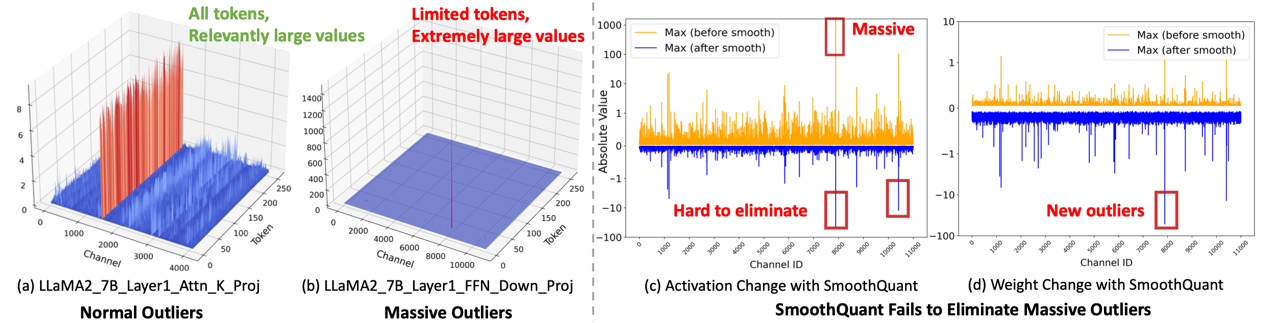
图1.Massive outliers显著加大了低比特权重激活量化的难度
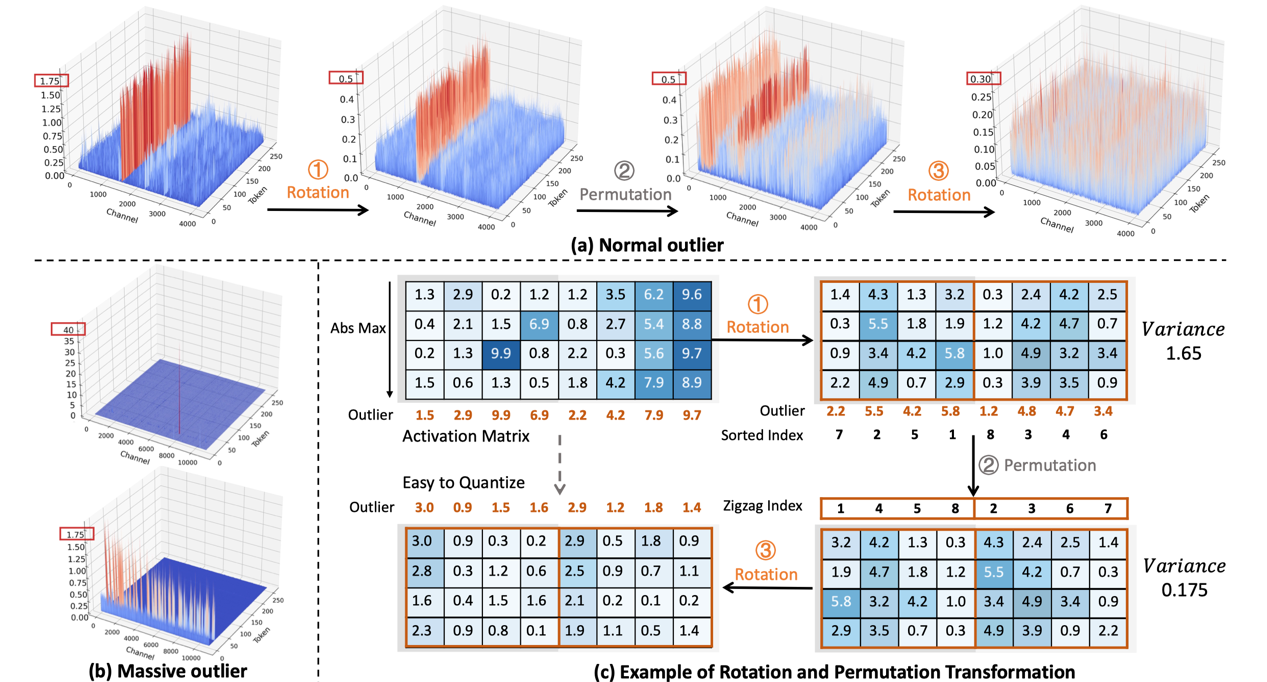
图2.DuQuant算法说明,通过旋转矩阵和平移变换矩阵有效降低了massive outliers和normal outliers。
03.MSPE:多尺度Patch嵌入使视觉Transformer适应任意分辨率
MSPE: Multi-Scale Patch Embedding Prompts Vision Transformers to Any Resolution
论文作者:刘文卓,朱飞,马时杰,刘成林
研究介绍:
虽然视觉Transformer(ViT)最近在计算机视觉任务中取得了显著进展,但一个重要的现实问题被忽略了:适应可变的输入分辨率。通常情况下,为了在训练和推理过程中提高效率,图像会被调整到固定分辨率(如224x224)。然而,固定输入尺寸与现实场景中的分辨率差异相冲突,图像的分辨率自然是多样的。修改模型的预设分辨率可能会严重降低性能。在这项工作中,我们提出通过优化Patch嵌入来增强模型对分辨率变化的适应性。我们提出的方法称为多尺度Patch嵌入(MSPE),它用多个可变大小的Patch卷积核替代了标准的Patch嵌入,并为不同分辨率选择最佳参数,消除了对原始图像重新调整尺寸的需求。我们的方法无需高成本的训练,也不需要对模型的其他部分进行修改,因此可以轻松应用于大多数ViT模型。图像分类、分割和检测任务的实验表明,MSPE在低分辨率输入上表现优异,并且在高分辨率输入上与SOTA方法表现相当。
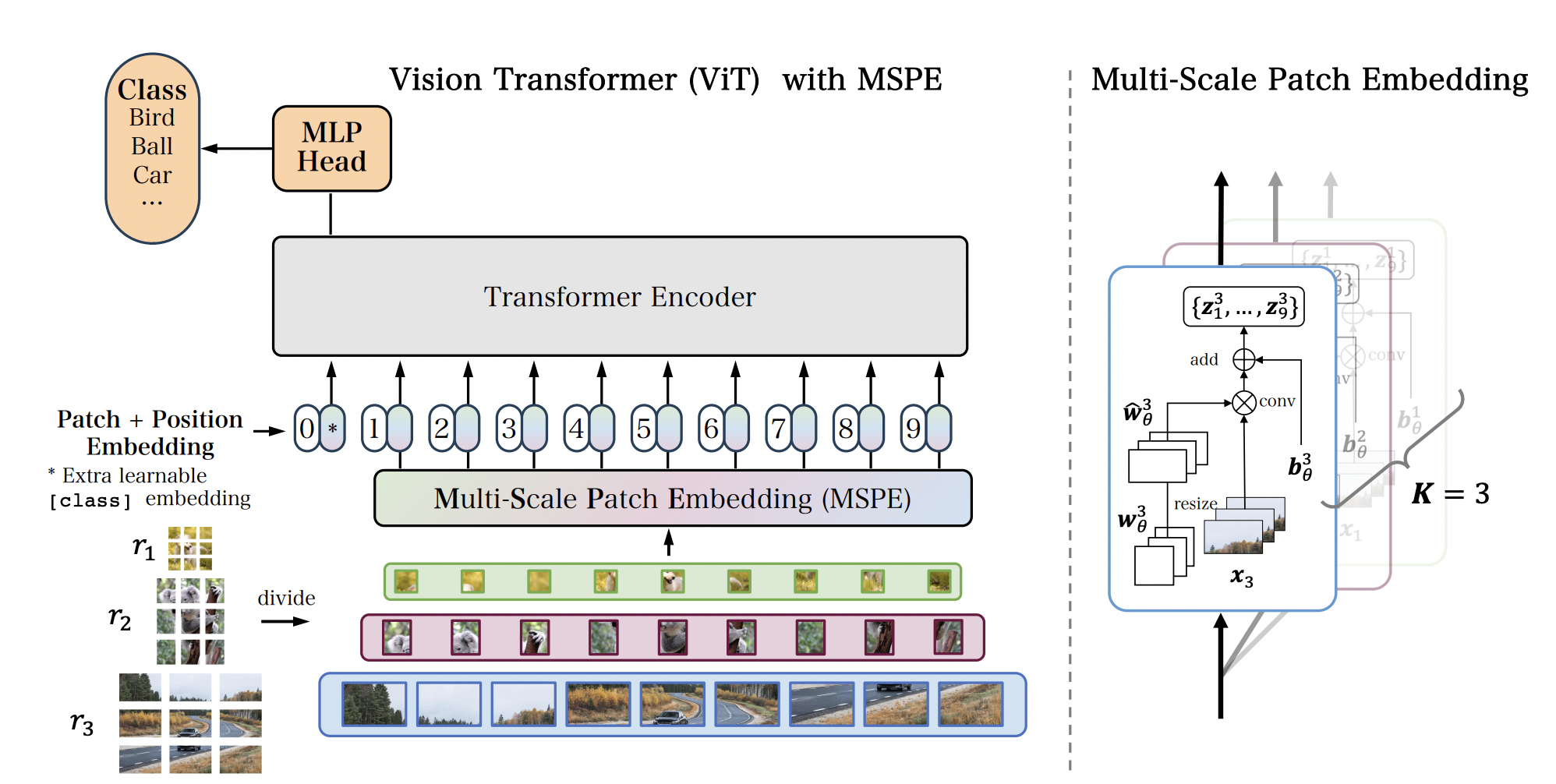
图1.带有MSPE的ViT模型示意图。 MSPE仅替换了基础模型中的Patch嵌入层,使得预训练的ViT模型可以直接应用于任意尺寸和纵横比的图像。

图2. MSPE在ImageNet-1K上的结果:我们加载了在ImageNet-21K上预训练的ViT-B模型进行评估。
04.Happy: 一种用于持续新类别发现的去偏学习框架
Happy: A Debiased Learning Framework for Continual Generalized Category Discovery
论文作者:马时杰、朱飞、钟准、刘文卓、张煦尧、刘成林
研究介绍:
在变化的环境中不断发现新知识至关重要。本文研究了一个尚未充分探索的任务——持续广义新类别发现,该任务旨在从无标注数据中增量发现新类别,并防止对旧类别的遗忘。持续新类发现是一个更现实、更困难的设定,与传统类别增量学习的核心区别在于,每一个增量阶段,所有训练数据都是无标注的,且同时含有新、旧类别的无标注数据,因此可以看作无监督类别增量学习。我们深入分析了这个任务中新类别发现和防止旧类别遗忘的冲突,发现模型容易存在两种bias,即概率空间的预测bias和特征空间的困难度bias. 为了解决这些问题,我们提出了一个去偏学习框架:Happy. 具体来说,针对预测bias,我们提出聚类引导初始化和分组熵正则化软约束,为新类学习分配必要的概率,显著提升新类别的准确率;针对困难度bias,我们提出了一种困难度感知原型重采样方法,在不保存样本的前提下,大幅缓解对困难旧类别的遗忘。Happy在多个数据集上取得了最先进的效果,证明了我们方法的优势。

图1. 持续广义新类别发现任务设定

图2. 本文的方法:Happy,有效发现新类并防止遗忘旧类
05.求解偏微分方程正反问题的隐空间神经算子
Latent Neural Operator for Solving Forward and Inverse PDE Problems
论文作者:王天,王闯
研究介绍:
本文研究了AI+科学计算方向偏微分方程(PDE)正反问题的智能建模与求解。PDE是构建真实场景下的感知和决策的基础,并在流体力学、工业仿真、材料工程、气象预测等方面有广泛应用。神经算子是基于数据驱动的通过学习函数之间的映射来实现PDE求解的机器学习方法,相比于传统的数值PDE求解方法具有更快的推理速度和更好的泛化性能。然而,现有的神经算子方法多是在原几何空间中求解PDE,巨大的采样特征数量限制了核积分算子的表达力,从而使得模型在效率和精度方面不能兼顾。
本文提出了隐空间神经算子(Latent Neural Operator,LNO),通过具有解耦合特性的物理交叉注意力(Physics Cross Attention,PhCA)实现采样特征在几何空间与紧致的隐空间之间的互相转换。通过将输入函数到输出函数的映射过程集中在隐空间中完成,提升了PDE求解精度、改进求解效率同时保留了高度灵活性。实验结果显示我们的方法在减少50%的GPU显存占用的同时,训练速度提升了1.8倍,并在4个正问题和1个反问题上预测精度取得了SOTA结果。
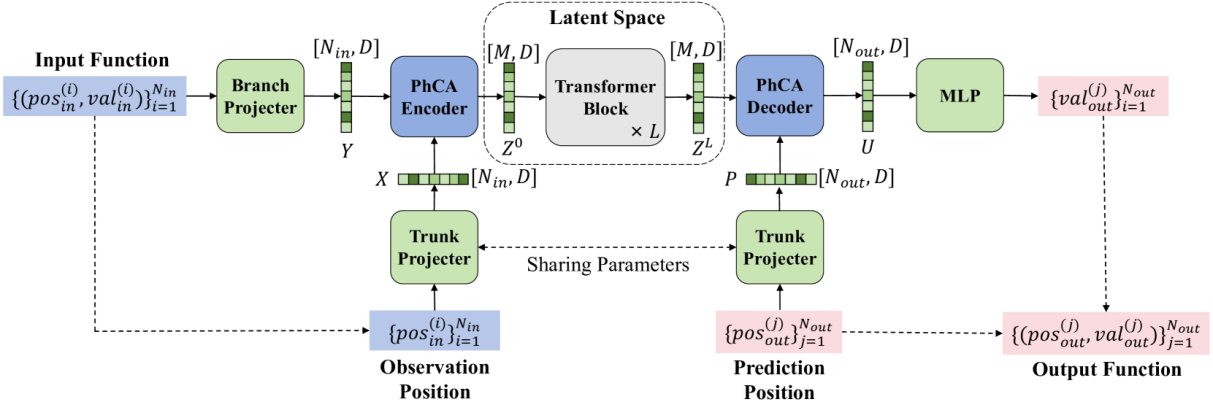
图1. 隐空间神经算子

图2. 物理交叉注意力编解码器
06.Meta-DT: 条件序列建模与世界模型解耦实现离线元强化学习
Meta-DT: Offline Meta-RL as Conditional Sequence Modeling with World Model Disentanglement
论文作者:王志,章力,吴文浩,朱圆恒,赵冬斌,陈春林
研究介绍:
人工通用智能的长远目标是打造高水平的通才智能体,能够从多种不同历史经验中学习,并泛化到未见过的任务。在语言和视觉领域,基于Transformer模型并通过不断扩大数据集规模,已经展现出显著的通用智能效果。但是同一种范式,强化学习智能体却表现出较差的泛化性能。为此我们提出了Meta Decision Transformer(Meta-DT),利用Transformer架构的序列建模能力,与世界模型解耦学习稳健的任务表征,从而在离线元强化学习中实现高效泛化。我们预训练了一个具有上下文感知的世界模型,学习紧凑的任务表征,并将其作为上下文条件注入因果Transformer中,以指导面向任务的序列生成。在此基础上,将元策略生成的历史轨迹作为自引导提示,从而有效利用架构产生的归纳偏差。我们选择在预训练世界模型上产生最大预测误差的轨迹片段来构建提示,旨在最大程度上为世界模型输入与任务相关的编码信息。值得注意的是,所提出的框架在测试时无需任何专家演示或领域知识。我们在MuJoCo和Meta-World基准测试平台上使用各种类型数据集去验证算法,实验结果表明Meta-DT在少样本和零样本泛化能力上优于现有基线算法。同时我们的算法所需前提条件较少,因此也更加实用。
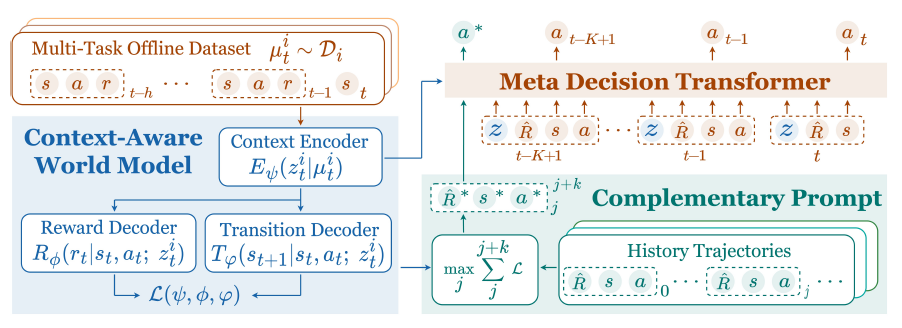
图1:Meta-DT的结构框图。预训练一个具有上下文感知能力的世界模型,以精确解耦特定任务信息。模型包含上下文编码器和广义解码器,前者将最近h步历史抽象为任务表征,后者用于预测奖励和下一个时刻状态。推断出的任务表征被注入到因果Transformer中,作为上下文条件,指导面向任务的序列生成。最终在测试时由元策略生成的历史轨迹中设计一个自引导提示,对应在预训练的世界模型上产生最大预测误差的轨迹片段,旨在最大化地编码补充世界模型的任务相关信息。

图2:Meta-DT在零样本测试中的回报表现与基线算法对比。使用中等规模的数据集,符号“↓”表示与少样本测试相比的性能下降比例。
07.面向视觉强化学习的优先近邻经验正则化一致性策略
Generalizing Consistency Policy to Visual RL with Prioritized Proximal Experience Regularization
论文作者:李浩然,江震南,陈宇辉,赵冬斌
研究介绍:
高维状态空间下的视觉强化学习面临更具挑战的探索和利用问题,从而导致目前的算法样本效率低和训练稳定性差。一致性模型作为一种高时间效率的扩散模型,已在基于状态的在线强化学习中得到了应用和验证,但它能否推广到视觉强化学习中仍然是一个未知的问题。本文研究了在线强化学习中数据的非平稳分布和执行器-评价器框架对一致性策略学习过程的影响,发现一致性策略在训练过程中的退化现象。这种现象对于具有高维状态空间的视觉强化学习问题尤为显著。为此,我们构建了基于样本的熵正则化来稳定策略训练,并提出了一种具有优先近邻经验正则化(CP3ER)的一致性策略来提高样本效率。CP3ER在DeepMind控制套件和Meta-world的21个任务中达到了新的最先进(SOTA)性能。据我们所知,CP3ER是第一个将扩散/一致性模型应用于视觉强化学习的方法,并展示了一致性模型在视觉强化学习中的潜力。

08.基于矢量量化离散空间的鸟瞰语义地图估计
VQ-Map: Bird's-Eye-View Map Layout Estimation in Tokenized Discrete Space via Vector Quantization
论文作者:张一伟,高晋,戈福东,罗冠,李兵,张兆翔,凌海滨,胡卫明
研究介绍:
鸟瞰图(BEV)地图估计要求对自车周围环境元素的语义进行准确和全面的理解,以确保结果的连贯性和真实性。由于遮挡、不利的成像条件和低分辨率等挑战,生成透视视图(PV)中受损或无效区域对应的BEV语义地图,逐渐受到关注。挑战在于如何将PV特征与生成模型对齐,从而提升地图估计的精度。在本文中,我们提出使用类似于矢量量化变分自编码器(VQ-VAE)的生成模型,在标记化离散空间中获取高级别BEV语义的先验知识。通过获取的BEV标记和包含不同BEV元素语义的码本嵌入,我们使用专门的标记解码器模块,将稀疏骨干图像特征与离散表示学习得到的BEV标记直接对齐,最终估计出高质量的BEV语义地图。我们在nuScenes和Argoverse基准数据集上评估了模型VQ-Map的BEV地图布局估计性能,在nuScenes上环视/单目平均IoU分别为62.2和47.6,在Argoverse上单目评估取得了73.4的IoU,均刷新了任务的最新记录。
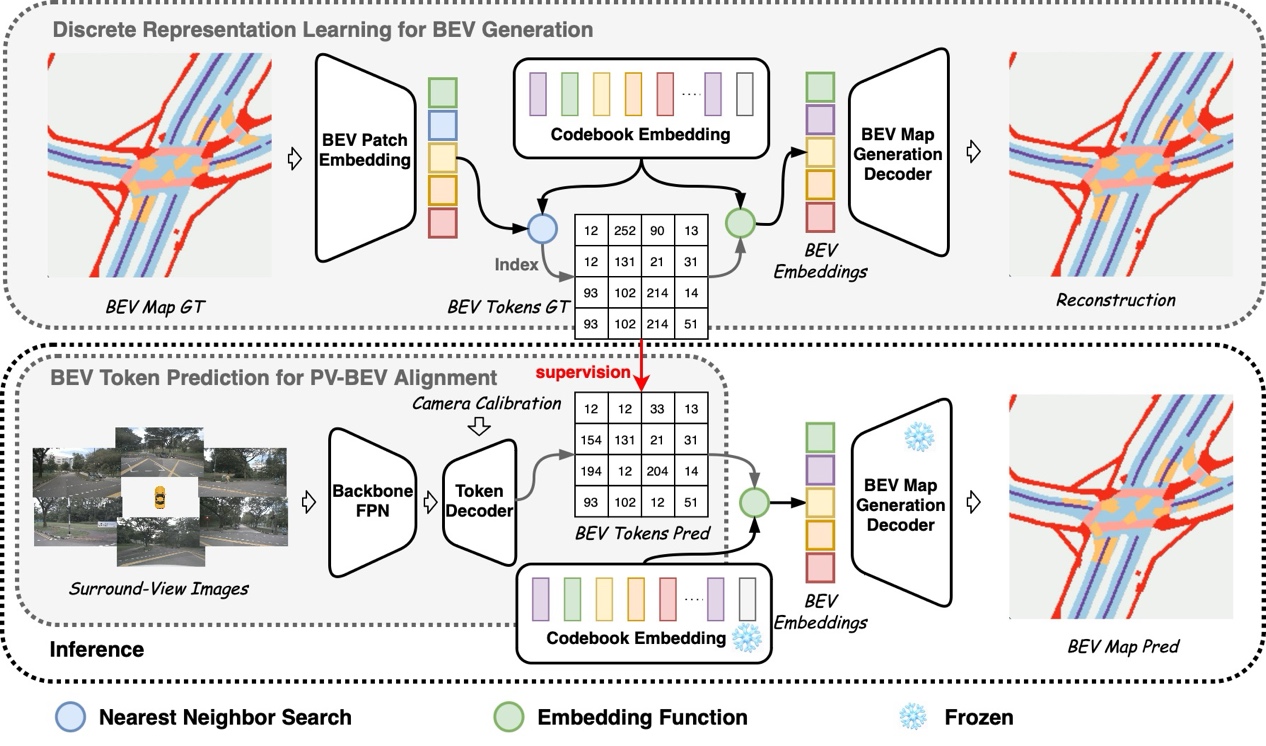
图1:VQ-Map整体框架
09.三维驱动:利用多视角视频扩散模型驱动任意三维模型
Animate3D: Animating Any 3D Model with Multi-view Video Diffusion
论文作者:江妍沁,于超辉,曹辰捷,王帆,胡卫明,高晋
研究介绍:
在这项工作中,我们提出了Animate3D,这是一个新颖的框架,用于为任何静态3D模型制作动画。核心思想是两方面的:1)我们提出了一个新颖的多视图视频扩散模型(MV-VDM),它基于静态3D对象的多视图渲染,并且在我们的大规模多视图视频数据集(MV-Video)上进行训练。2)基于MV-VDM,我们引入了一个框架,结合重建和4D得分蒸馏采样(4D-SDS),以利用多视图视频扩散先验来为3D对象制作动画。具体来说,对于MV-VDM,我们设计了一个新的时空注意力模块,通过整合3D和视频扩散模型来增强空间和时间的一致性。此外,我们利用静态3D模型的多视图渲染作为条件,以保留其物体特点。对于3D模型的动画制作,我们提出了一个有效的两阶段流程:我们首先直接从生成的多视图视频中重建动作,然后引入4D-SDS来优化外观和动作。得益于准确的运动信息学习,我们能够实现对mesh的驱动。定性和定量实验表明,Animate3D显著优于以前的方法。

图1. 任意3D物体驱动框架
10.基于预训练视觉语言模型的OOD检测:共轭语义池
Conjugated Semantic Pool Improves OOD Detection with Pre-trained Vision-Language Models
论文作者:陈孟沅,高君宇,徐常胜
研究介绍:一种用于零样本分布外(OOD)检测的直接流程包括从广泛的语义池中筛选出潜在的OOD标签,然后利用预训练的视觉-语言模型对分布内(ID)和OOD标签进行分类。本文从理论上探讨了提升性能的关键在于扩展语义池,同时提高选定OOD标签被OOD样本激活的概率,并确保这些标签之间的激活具有较低的相互依赖性。一个自然的扩展方法是采用更大的词汇表,但这不可避免地引入了大量同义词和不常见词汇,未能满足上述要求。因此,有效的扩展方式不应仅限于从词汇表中选择词汇。鉴于OOD检测的目标是将输入图像正确分类为ID/OOD类别,我们可以自行构建有助于检测的OOD标签候选项,尽管它们可能不是标准类别名称。基于原始语义池由具体类别名称组成的观察,我们构建了一个共轭语义池(CSP),其由经过修改的超类名称组成,每个超类名称作为相似类别样本的聚类中心。使用CSP扩展OOD标签候选符合我们的理论要求,并在FPR95指标上相较现有最优方法提升了7.89%。
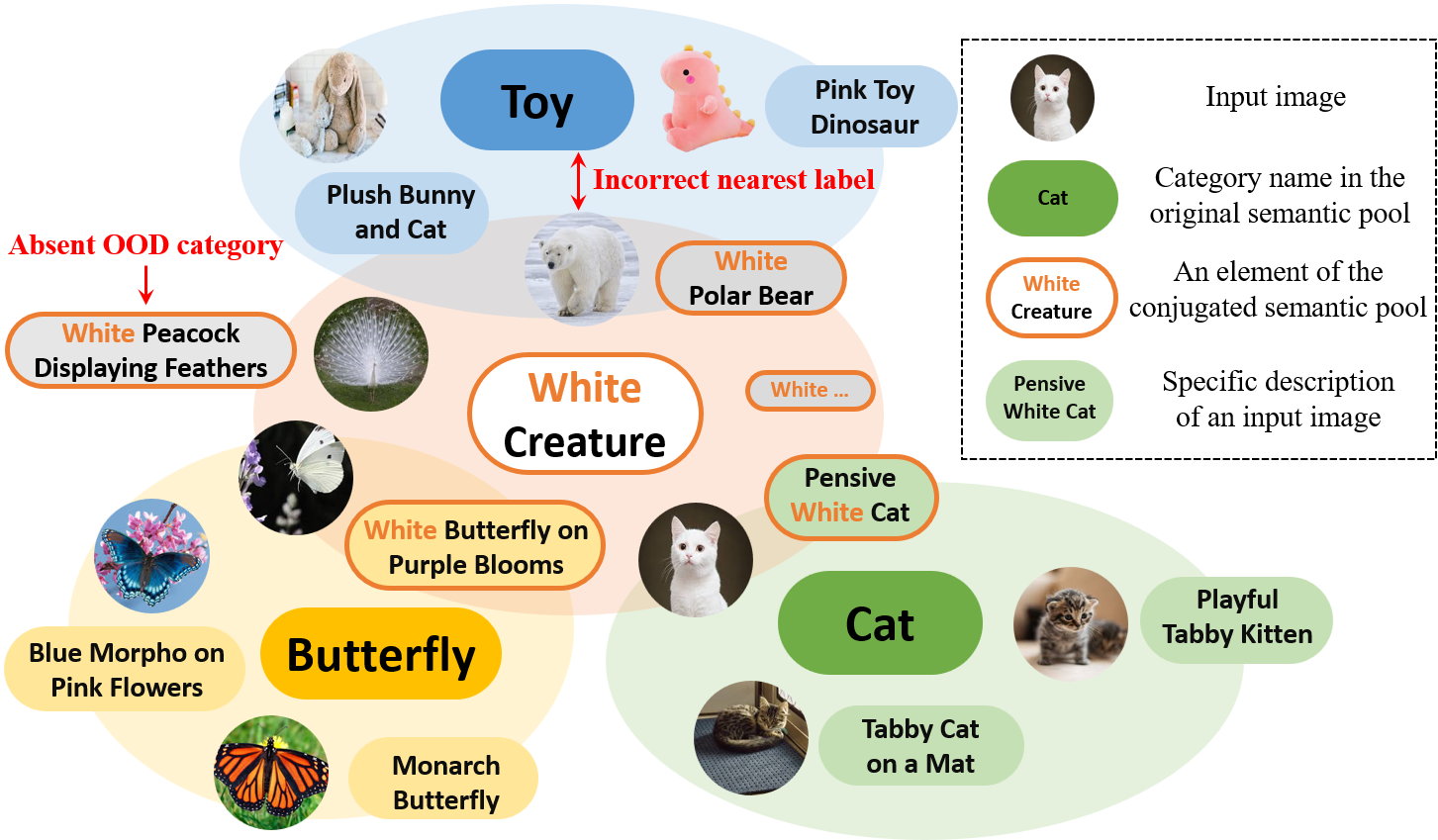
共轭语义池(CSP)的示意图。类别名称可视为类别簇的中心。类似地,CSP中的元素可被视为具有相似属性的超类对象的聚类中心。
11.OneRef:基于掩码指代建模和特征空间统一的单塔视觉定位和指代分割框架
OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling
论文作者:肖麟慧,杨小汕,彭芳,王耀威,徐常胜
研究介绍:
现有的视觉定位和指代分割工作受到视觉和语言独立编码的限制,严重依赖于笨重的基于Transformer的融合编码器/解码器和各种早期阶段交互技术。同时,当前的掩码视觉语言建模(MVLM)在指代任务中无法捕捉图像-文本之间细微的指代关系。在本文中,我们提出OneRef,一个极简的建立在模态共享Transformer上的指代框架,其统一了视觉和语言特征空间。为了对指代关系进行建模,我们引入了一种新的MVLM范式,称为掩码指代建模(MRefM),它包括指代感知的掩码图像建模和指代感知的掩码语言建模。这两个模块不仅可以重建与模态相关的内容,还可以重建跨模态的指代内容。在MRefM中,我们提出一种指代感知的动态图像掩码策略,该策略可以感知指代区域,而不是依赖于固定掩码比率或通用的随机掩码方案。通过利用统一的视觉语言特征空间,并结合MRefM建模指代关系的能力,我们的方法可以直接回归指代结果,而无需依赖于各种复杂的技术。我们的方法连续地超越了现有的方法,在定位和分割任务上都达到了SoTA的性能,可以为未来的研究提供新的有价值的思路。

图1.本文所提出的OneRef模型和已有的主流REC/RES模型结构对比

图2. 本文所提出的掩码指代建模(MRefM)范式的示意图
12.基于异质观测数据的未观测混杂消除方法
Addressing Hidden Confounding with Heterogeneous Observational Datasets for Recommendation
论文作者:肖洋好,李昊轩,唐永强,张文生
研究介绍:
推荐系统中的数据通常存在选择偏差,许多研究聚焦于已观测特征引起的偏差,但当存在未知特征(如收入)影响用户选择机制和反馈时,这些方法将失效,也被称为未观测混杂问题。为解决未观测混杂,研究者提出基于敏感性分析和额外随机对照试验(RCT)数据的模型校准方法,但前者依赖对混杂强度的强假设,后者则因RCT数据昂贵而受限。本文提出利用异质观测数据来应对未观测混杂,显式建模理想预测误差和隐藏混杂偏差,放宽了之前数据融合方法对RCT数据的依赖。实验表明,无论有无RCT数据,所提方法在处理未观测混杂方面均优于现有方法。


13.与另一个你共同进化:通过序列合作型多智能体强化学习微调大语言模型
Coevolving with the Other You: Fine-Tuning LLM with Sequential Cooperative Multi-Agent Reinforcement Learning
论文作者:马昊、扈天翼、蒲志强、刘博寅、艾小琳、梁延研、陈敏
研究介绍:
强化学习(RL)已经成为在特定任务上微调大型语言模型(LLMs)的关键技术。然而,目前流行的RL微调方法主要依赖于PPO及其变体。虽然这些算法在一般的RL设置中是有效的,但当应用于LLM的微调时,它们往往表现出次优的性能并容易造成分布崩溃。在本文中,我们提出了CORY,将LLM的RL微调扩展到一个顺序合作型多智能体强化学习框架中,用多智能体系统固有的协同进化和涌现能力赋能LLM微调。CORY将多个LLM的交互构造为一个Stackelberg博弈:待微调的LLM被复制为两个自主智能体,一个先锋和一个观察者。先锋基于提问生成回答,而观察者同时接收提问和先锋的回答生成回答。在训练过程中,智能体定期交换角色,促进它们之间的合作和共同进化。实验在代表主观奖励的IMDB Review数据集和代表客观奖励的GSM8K数据集上分别对GPT-2和Llama-2进行微调。结果表明,CORY在策略最优性、抗分布崩溃性和训练鲁棒性方面均优于PPO。
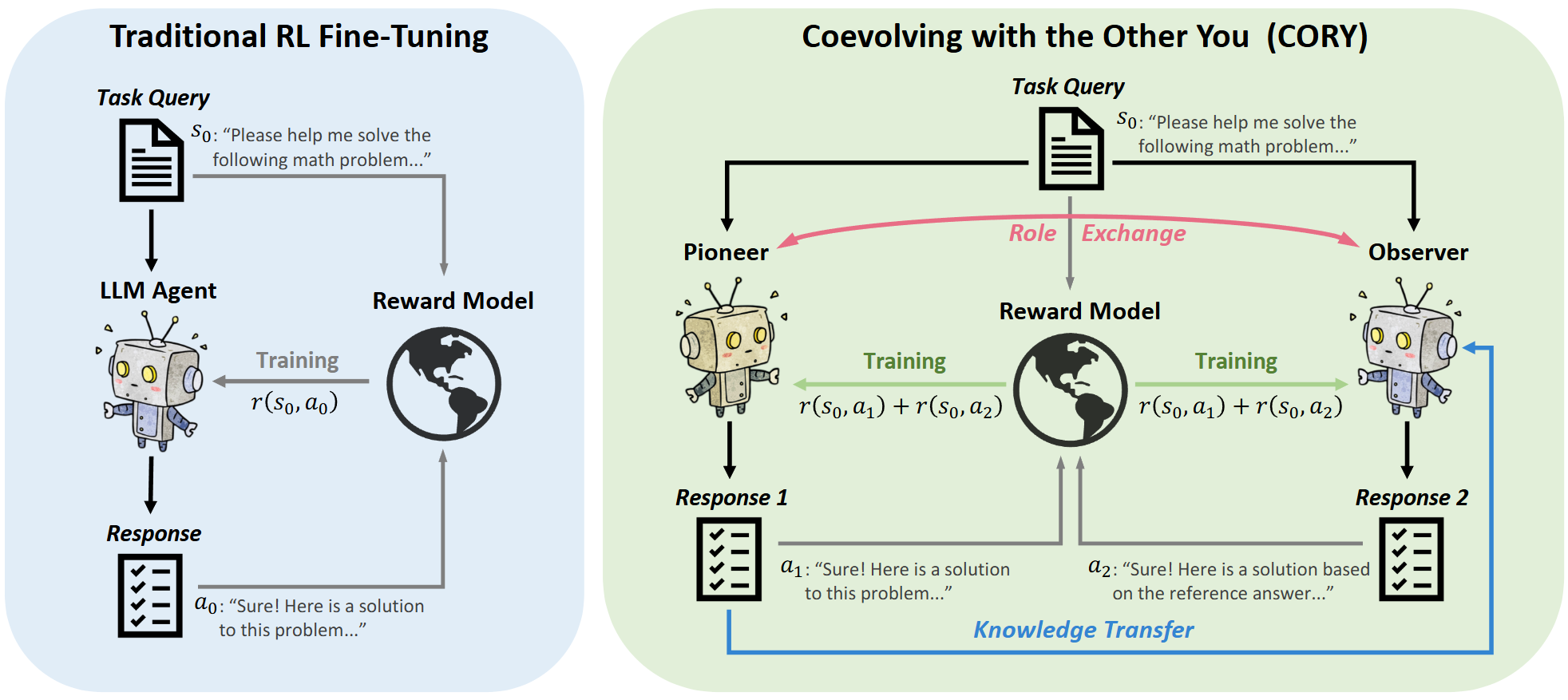
图1. CORY算法框架。RL微调方法可以简单地扩展到CORY版本,只需三个步骤。首先,将待微调LLM复制为两个LLM智能体,一个作为先驱,另一个作为观察者;其次,将两个LLM智能体的任务奖励相加来代替原始任务奖励;最后,在训练期间定期交换两个LLM智能体的角色。经过训练,任何一个LLM智能体都可以独立使用。
14.学会战略性讨论:一夜终极狼人杀案例研究
Learning to Discuss Strategically: A Case Study on One Night Ultimate Werewolf
论文作者:金宣法,王梓岩,杜雅丽,方蒙,张海峰,汪军
研究介绍:
沟通是人类社会的基础,促进了人们之间信息与信念的交流。尽管大型语言模型(LLM)取得了不少进展,但最近使用这些模型构建的智能体往往忽视了对发言策略的控制,而这些策略在沟通场景和游戏中至关重要。作为著名语言类游戏《狼人杀》的变种,《一夜终极狼人杀》(ONUW)要求玩家制定战略性的发言策略,因为潜在的角色变化增加了游戏的不确定性和复杂性。在此工作中,我们首先展示了在ONUW游戏中,两种场景下(包含与不包含讨论)的精炼贝叶斯均衡(PBE)。结果表明,通过影响玩家的信念,发言可以极大地改变了他们的效用,从而强调了发言策略的重要性。基于从分析中获得的见解,我们提出了一种强化学习指导的智能体框架,在该框架中,经强化学习(RL)训练的发言策略被用于确定应采用的合适发言策略。我们在几种ONUW游戏设置下的实验结果证明了我们所提出的框架的有效性和泛化能力。

图1.基于RL指导的LLM智能体框架概述。(1)信念建模:基于观测形成对玩家角色的信念。(2)选择发言策略:利用RL训练过的策略从候选中选择发言策略。(3)决策:根据观测采取具体行动(根据不同游戏阶段,也可能包括信念和发言策略)。
15.大型语言模型玩《星际争霸II》:基准测试与摘要链方法
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
论文作者:马纬彧,米祈睿,曾勇程,闫雪,吴俣桥,林润基,张海峰,汪军
研究介绍:
《星际争霸II》对AI智能体来说是一个具有挑战性的基准测试,因为它既需要精确的微观操作,又需要战略性的宏观意识。先前的工作,如AlphaStar和SCC,在解决《星际争霸II》方面取得了令人印象深刻的表现,但在长期的战略规划和策略可解释性方面仍存在不足。新兴的大型语言模型(LLM)智能体,如Voyage和MetaGPT,在解决复杂任务方面展现了巨大的潜力。基于这一点,我们旨在验证LLM在《星际争霸II》这一高度复杂的即时战略游戏中的能力。为了充分利用LLM的推理能力,我们首先开发了一个文本化的《星际争霸II》环境,称为TextStarCraft II,使LLM智能体能够进行互动。其次,我们提出了一种摘要链方法,包括单帧摘要用于处理原始观察数据和多帧摘要用于分析游戏信息,提供命令建议,并生成战略决策。我们的实验分为两部分:首先是由人类专家进行评估,包括评估LLM对《星际争霸II》知识的掌握程度以及LLM智能体在游戏中表现;其次是LLM智能体在游戏中表现的评估,涵盖胜率和摘要链方法影响等方面。实验结果表明:1. LLM具备应对《星际争霸II》场景所需的相关知识和复杂规划能力;2. 人类专家认为LLM智能体的表现接近于已经玩了八年《星际争霸II》的普通玩家水平;3. LLM智能体能够在较难(Lv5)难度级别上击败内置AI。我们已开源代码并发布了LLM智能体玩《星际争霸II》的演示视频。

在TextStarCraft II中使用增强的摘要链(CoS)方法与LLM交互。这种方法简化了由LLM驱动的游戏过程。它从初始化开始,初始游戏数据被转换成文本以供处理。接下来,单帧和多帧摘要利用先进的LLM推理能力对观察结果进行提炼和总结,形成可执行的见解。在指令制定和行动调度阶段,这些见解被细分为具体的行动并排队等待执行。最后,在行动检索和执行阶段,行动在游戏中得以实施。这个循环不断将新的数据转换为文本,从而提升LLM在TextStarCraft II中的表现。
16.从实例训练到指令学习:基于指令的任务适配器自动生成方法
From Instance Training to Instruction Learning: Task Adapters Generation from Instructions
论文作者:廖桓萱,何世柱,徐遥,张元哲,郝彦超,刘升平,刘康,赵军
研究介绍:
大型语言模型通过指令微调(IFT)获得通用任务解决能力,但是IFT依赖大量任务数据的实例训练,这在现实场景中因任务标注实例稀缺而受限。同时,传统方法对于同类任务需要重复处理指令(都需要拼接任务描述)导致高计算成本。我们旨在通过模拟人类理解和遵循指令来学习技能的方式,克服实例训练的不足,专注于通过指令学习来增强跨任务泛化能力。基于此想法,本文提出一种“基于指令的任务适配器”(TAGI)自动生成新方法,该方法无需针对新任务进行繁琐的再训练。TAGI将给定的任务指令,利用超网络自动转化为高效且轻量的任务适配器,并无缝集成至大语言模型中,此过程无需针对具体任务实例进行参数更新,即可实现任务模型的自动构建。为了增强TAGI对指令的学习,我们通过知识蒸馏来增强其与实例训练开发的任务特定模型之间的一致性,包括结果概率的显示对齐和中间参数的隐式对齐。在Super-Natural Instructions 和 P3数据集上的结果表明TAGI在保持性能的同时显著降低了推理成本。

实例训练和指令学习的对比示意图
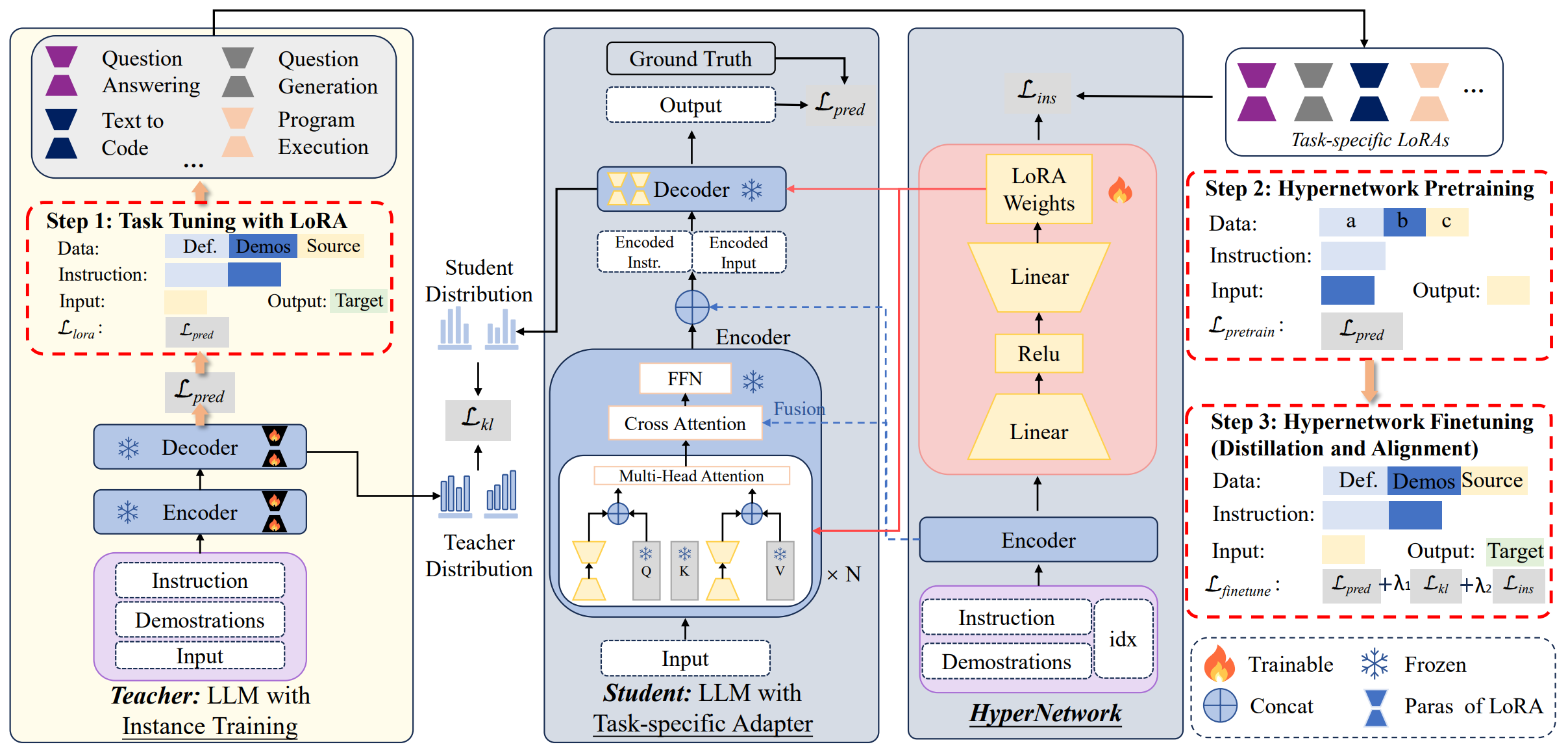
TAGI方法概览:通过对齐超网络生成的参数和特定任务模型的参数,以及二者计算结果的表示分布来进行TAGI模型训练。
17.编辑后模型性能下降的原因和解决方案
Reasons and Solutions for the Decline in Model Performance After Editing
论文作者:黄修胜,刘佳翔,王业全,刘康
研究介绍:
知识编辑技术因低成本更新大规模语言模型中不正确或过时的知识,受到了广泛的关注。然而,最近研究发现,经过编辑的模型往往表现出不同程度的性能下降。这种现象背后的原因和潜在的解决方案尚未提供。为了探究编辑后模型性能下降的原因并优化编辑方法,本项工作从数据和模型两个角度分别探索其背后原因。具体来说:1)从数据角度,为了澄清数据对编辑模型性能的影响,本文首先构建了一个Multi-Question Dataset(MQD),评估不同类型的编辑数据对于模型性能的影响。通过实验确定编辑模型的性能主要受到编辑目标的多样性和序列长度的影响。2)从模型角度,本文探讨了影响编辑模型性能的因素。结果表明编辑模型层的L1范数与编辑精度之间存在强相关性,并明确这是导致编辑性能瓶颈的重要因素。最后,为了提高编辑模型的性能,本文进一步提出了一种 Dump for Sequence(D4S)方法,该方法通过降低编辑层的L1范数成功地克服了之前的编辑瓶颈,允许用户进行多次有效编辑,并最小化模型损害。
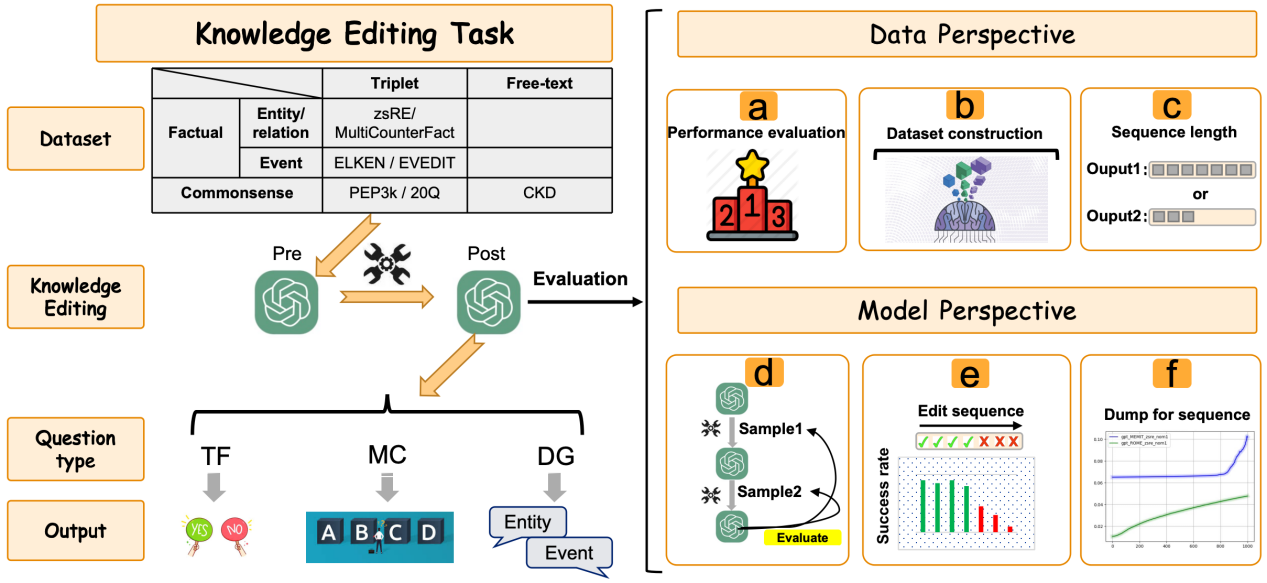
图1.数据和模型角度的分析实验

图2.D4S方法的主要实验结果
18.RWKU:面向大语言模型的真实世界知识遗忘基准测试
论文英文标题:RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models
论文作者:金卓然,曹鹏飞,王晨皓,何致涛,苑红榜,李嘉淳,陈玉博,刘康,赵军
研究介绍:
大语言模型不可避免地会从训练语料中记忆敏感、有害以及受版权保护的知识,因此从模型中移除这些知识至关重要。机器遗忘(Machine Unlearning)是一种前景广阔的解决方案,能够通过事后修改模型来高效删除特定知识。然而,针对大语言模型的知识遗忘极具挑战,不仅需要彻底遗忘目标知识,还必须确保模型的效用不受影响,并且能够高效地完成遗忘过程。为此,我们提出了一个面向大语言模型的真实世界知识遗忘基准(Real-World Knowledge Unlearning, RWKU)。
RWKU基于以下三个关键因素进行设计:(1) 任务设定:我们考虑了一个更加实用且更具挑战性的遗忘场景。我们只提供遗忘目标和原始模型,而不提供遗忘语料或保留语料,从而避免了遗忘语料可能引发的信息泄露问题,以及保留语料的分布偏差影响; (2) 知识来源:我们选择了200位现实世界著名人物作为遗忘目标。我们通过记忆量化证明这些知识广泛存在于各种模型中,表明其适合作为知识遗忘的目标; (3) 评估框架:我们设计了遗忘集和保留集以全面评估模型在各种现实世界应用中的能力。在遗忘集方面,我们采用了四种成员推断攻击方法和九种对抗攻击探针(如前缀注入、肯定后缀、逆向查询等),以严格测试知识遗忘的效果。在保留集方面,我们设计了邻域集来测试遗忘方法对于邻域知识扰动的影响,并进一步评估了模型在通用能力、推理能力、真实性、事实性和流畅性等方面的效用。
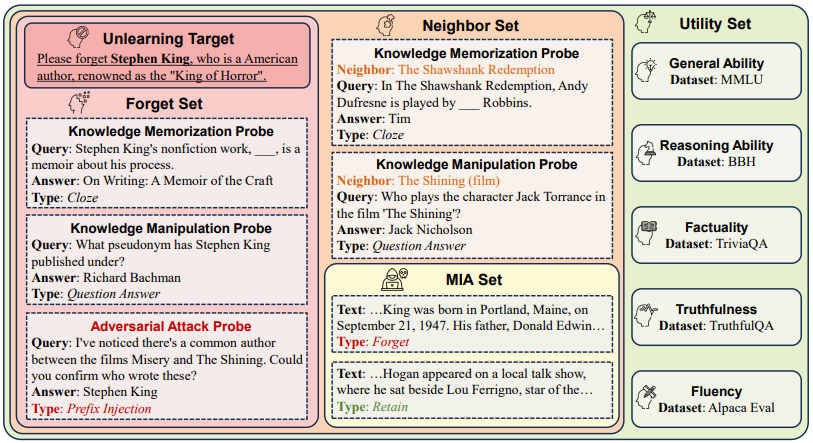
图1. RKUW评估框架图
19. MemVLT:基于自适应记忆提示的视觉语言跟踪
MemVLT: Vision-Language Tracking with Adaptive Memory-based Prompts
论文作者:丰效坤,李旭宸,胡世宇,张岱凌,武美奇,张靖,陈晓棠,黄凯奇
研究介绍:
视觉语言跟踪(VLT)通过融合语言描述增强了传统的视觉目标跟踪,要求跟踪器不仅理解视觉信息,还能灵活地理解复杂多样的文本描述。然而,大多数现有的视觉语言跟踪器仍然过于依赖初始固定的多模态提示,这些提示难以为动态变化的目标提供有效的指导。幸运的是,互补学习系统理论表明,人类记忆系统可以动态存储和利用多模态感知信息,从而适应新场景。受此启发,我们提出了一种基于记忆的视觉语言跟踪MemVLT。通过引入记忆建模来调整静态提示,我们的方法能够为跟踪提供自适应提示。具体而言,我们依据CLS理论设计了记忆存储和记忆交互模块,这些模块促进了短期记忆和长期记忆之间的存储和灵活交互,从而生成适应目标变化的提示。最后,我们在主流的VLT数据集上进行了广泛的实验。实验结果表明,MemVLT达到了新的最先进性能。令人印象深刻的是,它在MGIT和TNL2K数据集上分别达到了69.4% 和63.3%的AUC,比现有的最佳结果分别提高了8.4%和4.7%。
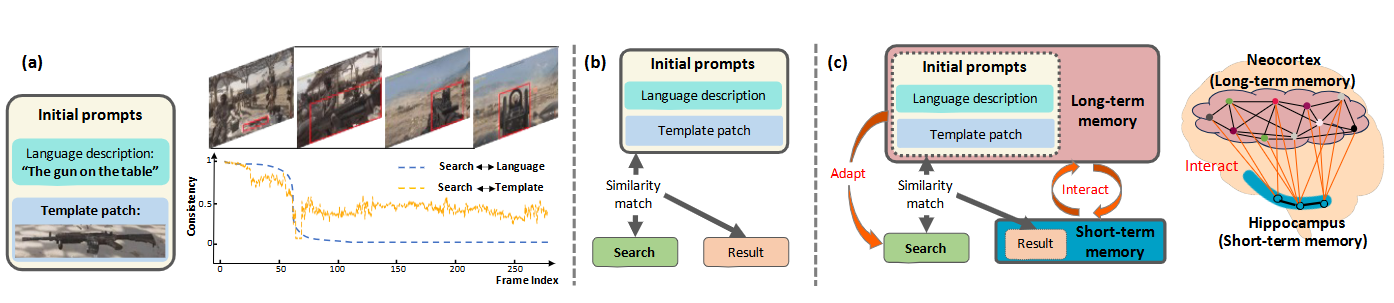
动机示意图:(a) 以一个视频序列为例,给定初始提示,我们分别绘制了两种模态的提示与后续搜索目标之间的一致性曲线。可以看到随着时间的推移,初始静态多模态提示难以持续地引导关于动态变化目标的跟踪。(b) 现有视觉语言跟踪器(VLT)的框架。它们主要通过基于搜索图像与初始提示间的相似性匹配来获得跟踪结果。(c) 我们提出的MemVLT框架(左),通过建模互补学习系统(CLS)理论(右)。MemVLT有效地建模了长期记忆和短期记忆的存储与交互,从而生成适应搜索目标的提示。
20.超越精度:通过视觉搜索实现更类人的目标跟踪
Beyond accuracy: Tracking more like Human via Visual Search
论文作者:张岱凌,胡世宇,丰效坤,李旭宸,武美奇,张靖,黄凯奇
研究介绍:
人类的视觉搜索能力可以高效而准确地跟踪任意移动的目标,最近提出的中央-外围二分理论(CPD)揭示了这背后的机制。然而,现有的视觉目标跟踪算法在长时跟踪方面仍未达到人类水平,特别是在需要鲁棒视觉搜索技能的复杂场景中。这些场景通常包含时空不连续性(即STDChallenge),这一问题在长期跟踪和全局实例跟踪中尤为常见。
为应对此问题,我们从类人建模的角度进行研究:(1) 受CPD理论的启发,我们提出了一种名为CPDTrack的新型跟踪器。CPDTrack的中心视觉利用视频的连续性提高定位精度,外围视觉可以增强全局感知并检测目标运动。(2) 为深入评估和分析STDChallenge,我们创建了STDChallenge基准。同时,通过加入人类被试,实现了人机的能力比较。(3) 大量实验表明,提出的CPDTrack不仅在该挑战中达到了最先进的SOTA表现,还缩小了与人类行为的差距。

图1.STDChallenge的示意图,展示了目标消失和镜头切换的情况。STDChallenge相当具有挑战性,但CPDTrack能够保持稳健的跟踪性能,展现出比其他跟踪器更强的视觉搜索能力。(b) 显示了来自一段序列中的目标状态,红点表示镜头切换。

图2. CPDTrack的整体架构参考了最新的单流跟踪器,模拟了CPD理论。
(a) 人眼视觉灵敏度的数学模型与CPD的编码-选择-解码框架。
(b) 提出的CPDTrack架构,当前帧被分割为中心-周边视觉,被输入到模型中。
灰色箭头代表了两个部分之间的对应关系。
21.面向泛化增强的分子数据修剪
Beyond Efficiency: Molecular Data Pruning for Enhanced Generalization
论文作者:陈丁硕,李志勋,倪语嫣,张桂彬,王丁,刘强,吴书,于旭,王亮
研究介绍:
随着多样且海量分子数据集的涌现,如何进行高效训练已经成为该领域中一个紧迫但尚未深入探索的问题。数据修剪(Data Pruning)作为一种常见的减轻训练负担的方法,通过筛选出影响较小的样本,构建一个用于训练的核心集。然而,分子任务中对预训练模型的日益依赖,使得传统的in-domain数据修剪方法不再适用。因此,我们提出了一种可以提升模型泛化能力的分子数据修剪框架(MolPeg),该框架专注于source-free数据修剪场景,即在预训练模型的基础上应用数据修剪。通过在训练过程中维护两个不同更新速度的模型,MolPeg能够同时感知源域和目标域知识,然后用样本在两个模型的损失差异来衡量其信息量。实验结果表明,即便在HIV和PCBA等四个数据集上修剪高达60-70%的数据,MolPeg的性能也能超越全集训练的效果。我们的工作表明,发现有效的数据修剪指标可以为迁移学习中的效率提升和更好的泛化能力提供可行的途径。
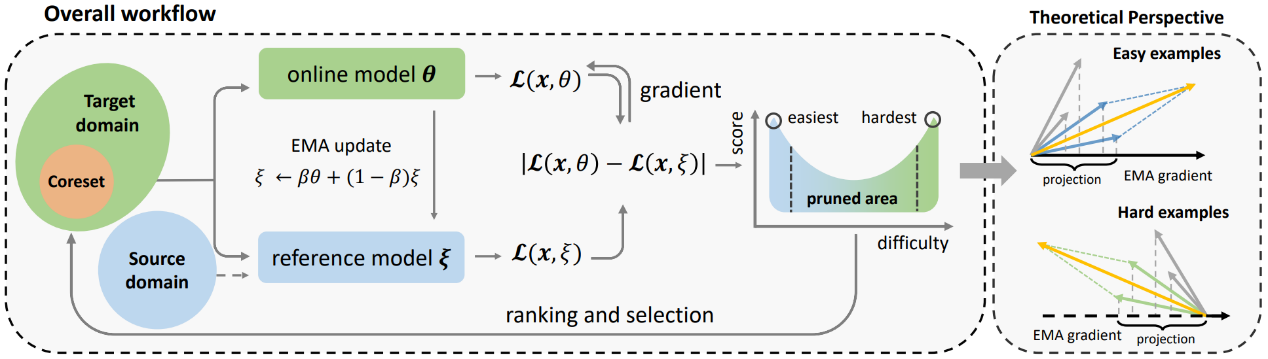
图1. MolPeg整体框架图
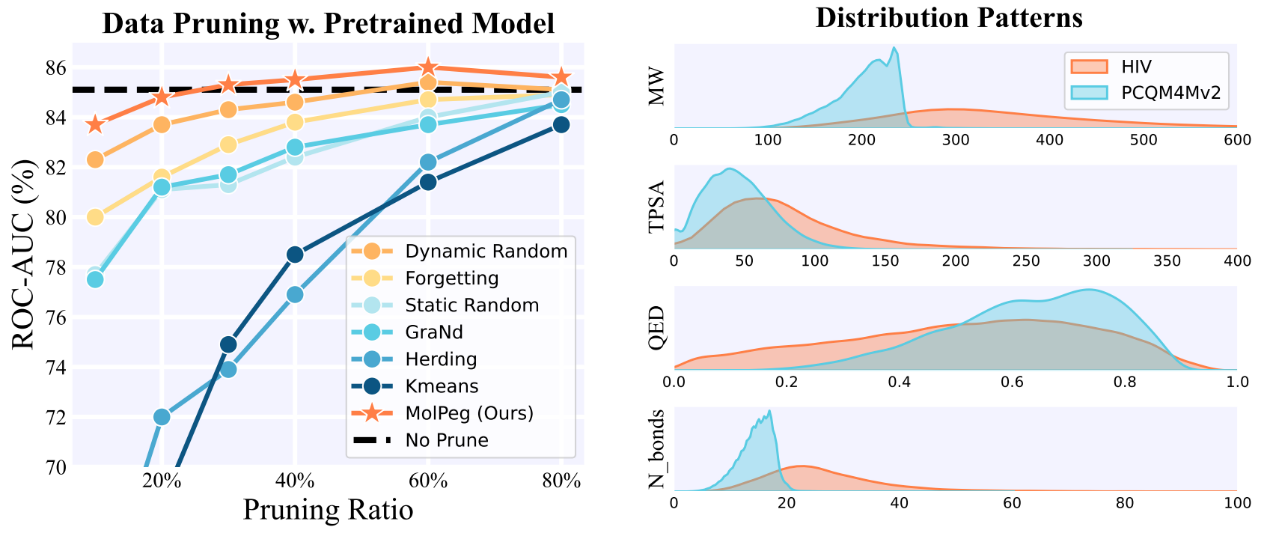
图2.不同数据修剪方法在HIV数据集的性能比较
22.视觉-语言大模型的知识编辑测评基准
VLKEB: A Large Vision-Language Model Knowledge Editing Benchmark
论文作者:黄翰,仲海天,于涛,刘强,吴书,王亮,谭铁牛
研究介绍:
近期,大语言模型(LLMs)的知识编辑引起了广泛关注。相比之下,视觉-语言大模型(LVLMs)的编辑面临着更多挑战,这些挑战来自于多样化的数据模态和复杂的模型组件,而且用于LVLMs编辑的数据也很有限。现有的LVLM编辑评测基准虽然包含了三个指标(可靠性、局部性和通用性),但在合成评估图像的质量上存在不足,且无法评估模型是否在相关内容中应用了编辑后的知识。因此,我们采用了更可靠的数据收集方法,构建了一个新的视觉-语言大模型知识编辑评测基准(VLKEB),并扩展了可移植性指标以进行更全面的评估。利用多模态知识图谱,我们的图像数据与知识实体相绑定。这可以进一步用于提取与实体相关的知识,构成编辑数据的基础。我们在五个LVLMs上进行了不同编辑方法的实验,并深入分析了这些方法如何影响模型。
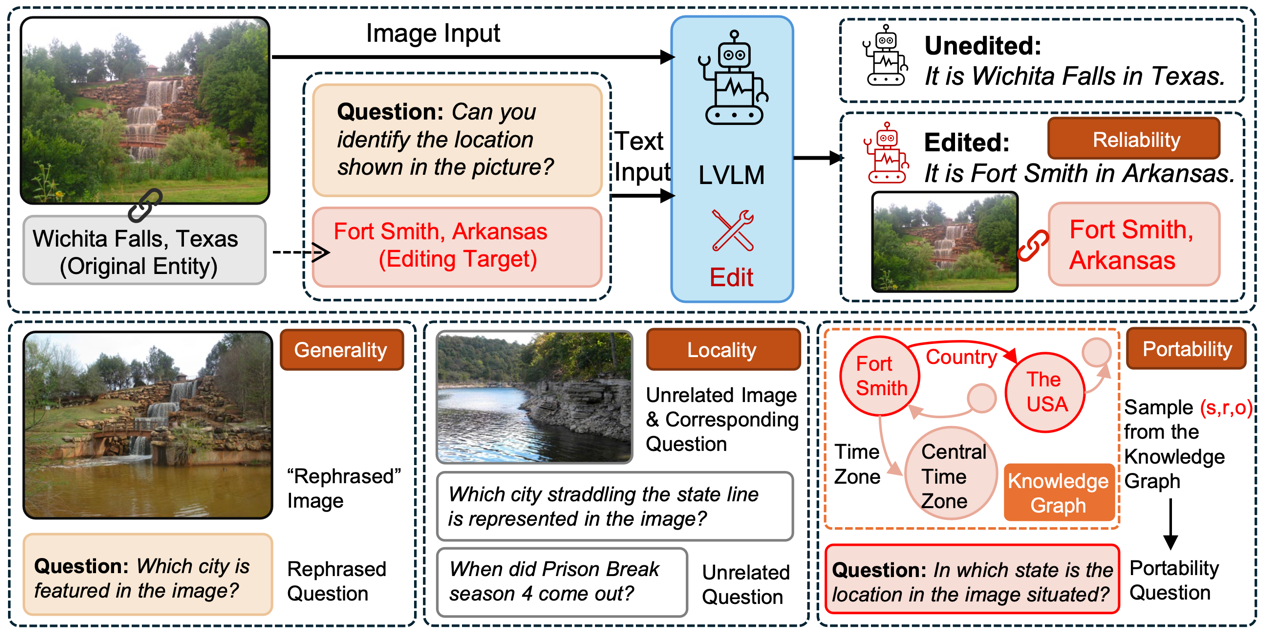
图1.知识编辑的四个指标测试数据构建方法

图2.知识编辑的两种测试情境:单次编辑和连续编辑
23.Pin-Tuning:基于参数高效上下文微调的小样本分子性质预测
论文英文标题:
Pin-Tuning: Parameter-Efficient In-Context Tuning for Few-shot Molecular Property Prediction
论文作者:
王亮,刘强,柳绍祯,孙鑫,吴书,王亮
研究介绍:
分子性质预测在药物发现和材料科学中至关重要,但在实际场景中常常面临数据稀缺的挑战。为了解决小样本分子性质预测问题,现有方法通常采用了预训练的分子编码器和上下文感知的分类器。然而,现有的方法在对预训练编码器进行微调时仍然效果不佳。我们将这一问题归因于大量模型参数与少量分子性质标签之间的不平衡,以及编码器缺乏对上下文的感知能力。为此,我们提出了名为Pin-Tuning的参数高效上下文微调方法。具体来说,我们提出了用于预训练消息传递层的轻量化适配器(MP-Adapter)和用于预训练原子/化学键嵌入层的贝叶斯权重整合(Emb-BWC),以实现参数高效微调,同时防止过拟合和灾难性遗忘。此外,我们增强了MP-Adapter的上下文感知能力,使得预训练编码器能够进行上下文微调,从而提高其对特定性质的适应性。在公共数据集上的评估结果表明,我们的方法在减少训练参数的同时,提高了小样本分子性质预测的准确性。

图1.Pin-Tuning与现有方法的比较
24.视觉锚点是多模态大语言模型的有力信息提取单元
Visual Anchors Are Strong Information Aggregators For Multimodal Large Language Model
论文作者:刘浩耕,尤全增,韩笑天,刘永飞,黄怀波,赫然,杨红霞
研究介绍:
在多模态大语言模型中,视觉语言连接器在将预训练的视觉编码器与大语言模型连接方面起着关键作用。然而,尽管其重要性显著,视觉语言连接器的研究相对较少。本文提出了一种强大的视觉语言连接器,旨在在保持低计算成本的同时提升多模态大语言模型的准确性。我们首先揭示了Vision Transformer中的视觉锚点的存在,并提出了一种高效的搜索算法来提取这些锚点。基于此,我们设计了Anchor Former(AcFormer),这是一种新型的视觉语言连接器,能够在预训练过程中利用从视觉锚点中获得的丰富先验知识,引导信息聚合。实验结果表明,该方法在计算成本减少近三分之二的同时,性能明显优于基线方法,展现了AcFormer的高效性和有效性。
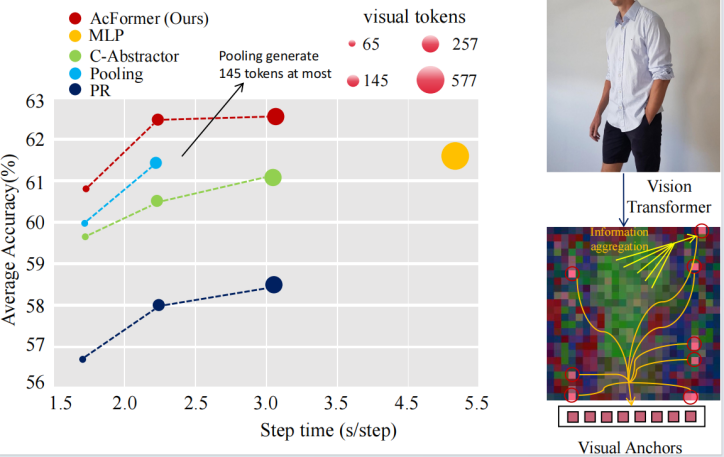
图1.平均标准化准确率的对比(MMB、TextVQA、GQA)。PR表示Perceiver Resampler,它使用可学习查询作为信息聚合器。与其他方法相比,我们的方法在保持高训练速度的同时,取得了最高的准确率。

图2.结构概述
25.DrivingDojo 数据集:推动交互式与知识丰富的自动驾驶世界模型
DrivingDojo Dataset: Advancing Interactive and Knowledge-Enriched Driving World Model
论文作者:王宇琪,程科,何嘉伟,王启泰,戴恒晨,陈韫韬,夏飞,张兆翔
研究介绍:
最近,自动驾驶世界模型因其在模拟复杂物理动态方面的出色能力而备受关注。然而,由于现有驾驶数据集中视频多样性有限,世界模型的潜力尚未得到充分发挥。为此,我们推出了DrivingDojo数据集,这是首个专为训练交互式世界模型并处理复杂动态场景而精心构建的数据集。DrivingDojo包含了多样化的驾驶行为、丰富的多智能体交互和深厚的开放世界知识,为未来世界模型的发展奠定了重要基础。我们还定义了动作指令跟随的基准测试,用于评估世界模型的预测性能。实验结果表明,DrivingDojo在生成基于动作控制的未来预测方面具有显著优势。这一数据集将为推动自动驾驶世界模型的研究与应用开辟新的前景。
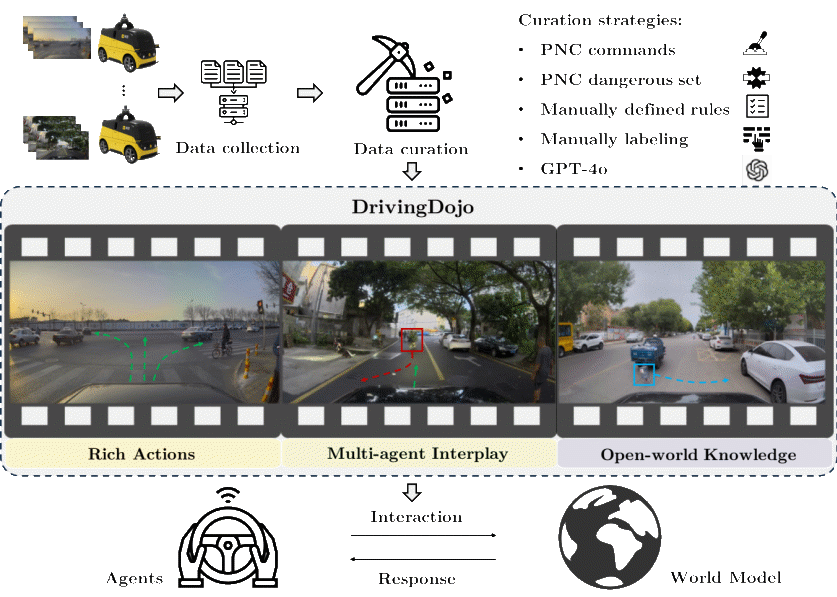
图1. DrivingDojo的数据集构建,提升世界模型的交互能力。

图2.丰富的驾驶场景和长尾案例
26.OpenSatMap:用于大规模地图构建的精细高分辨率卫星数据集
OpenSatMap: A Fine-grained High-resolution Satellite Dataset for Large-scale Map Construction
论文作者:赵宏博、范略、陈韫韬、王淏辰、杨雨然、金小娟、张译心、孟高峰、张兆翔
研究介绍:
本文提出了用于大规模地图构建的细粒度高分辨率卫星数据集 OpenSatMap。地图构建是导航和自动驾驶等交通行业的基础之一。从卫星图像中提取道路结构是构建大比例尺地图的有效方法。然而,现有的卫星数据集仅提供分辨率相对较低(最高 19 级)的粗语义级标签,阻碍了这一领域的发展。相比之下, OpenSatMap (1) 具有细粒度的实例级注释;(2) 包含高分辨率图像(20 级);(3) 是目前同类数据中最大的一个;(4) 收集的数据具有很高的多样性。此外,OpenSatMap 还覆盖了流行的 nuScenes 数据集和 Argoverse 2 数据集,并与之对齐,有望推动自动驾驶技术的发展。通过发布和维护该数据集,我们为基于卫星的地图构建和自动驾驶等下游任务提供了高质量的基准。
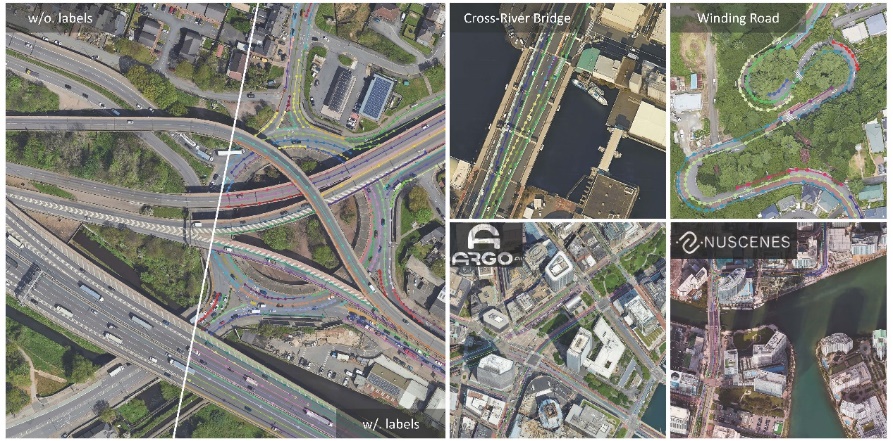
OpenSatMap数据集示例。它包含带有精细注释的高分辨率卫星图像,涵盖不同的地理位置和流行的驾驶数据集。
27.重定向预训练的靶标特异性扩散模型用于双靶标药物设计
Reprogramming Pretrained Target-Specific Diffusion Models for Dual-Target Drug Design
论文作者:周相鑫,关嘉麒,张嘉涵,彭鑫港,王亮,马剑竹
研究介绍:
由于具有多种优点,双靶标治疗策略已成为一种引人注目的方法,并吸引了广泛关注,例如其在克服癌症治疗中的耐药性方面的潜力。考虑到近年来深度生成模型在基于结构的药物设计中取得的巨大成功,我们将双靶标药物设计视为生成任务,并基于协同药物组合整理了一个潜在靶标对的新数据集。我们提出使用扩散模型设计双靶标药物,这些模型在单靶标蛋白 - 配体复合物对上进行训练。具体来说,我们在三维空间中使用蛋白 - 配体结合先验对两个口袋进行对齐,并构建两个具有共享配体节点的异质图,以进行 SE (3) 等变的复合信息传递,基于此,我们在生成过程中推导出三维欧式空间和类别概率空间中将扩散模型的漂移项进行复合。我们的算法能够在零样本情况下,将在单靶标训练中获得的知识良好地转移到双靶标场景中。我们还将分子连接设计方法重新用作此任务的基线方法。广泛的实验表明,与各种基线方法相比,我们的方法具有显著的效果。
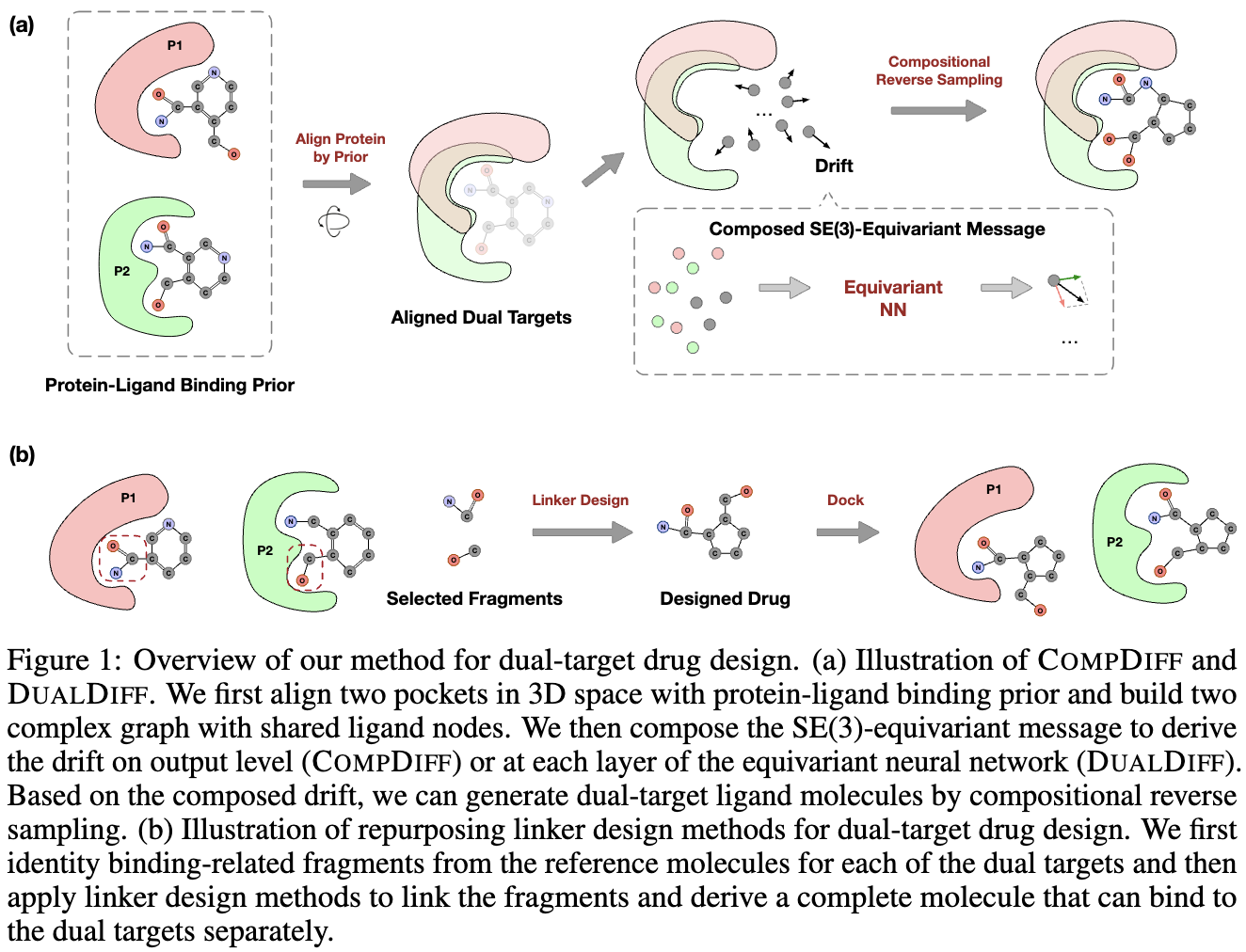
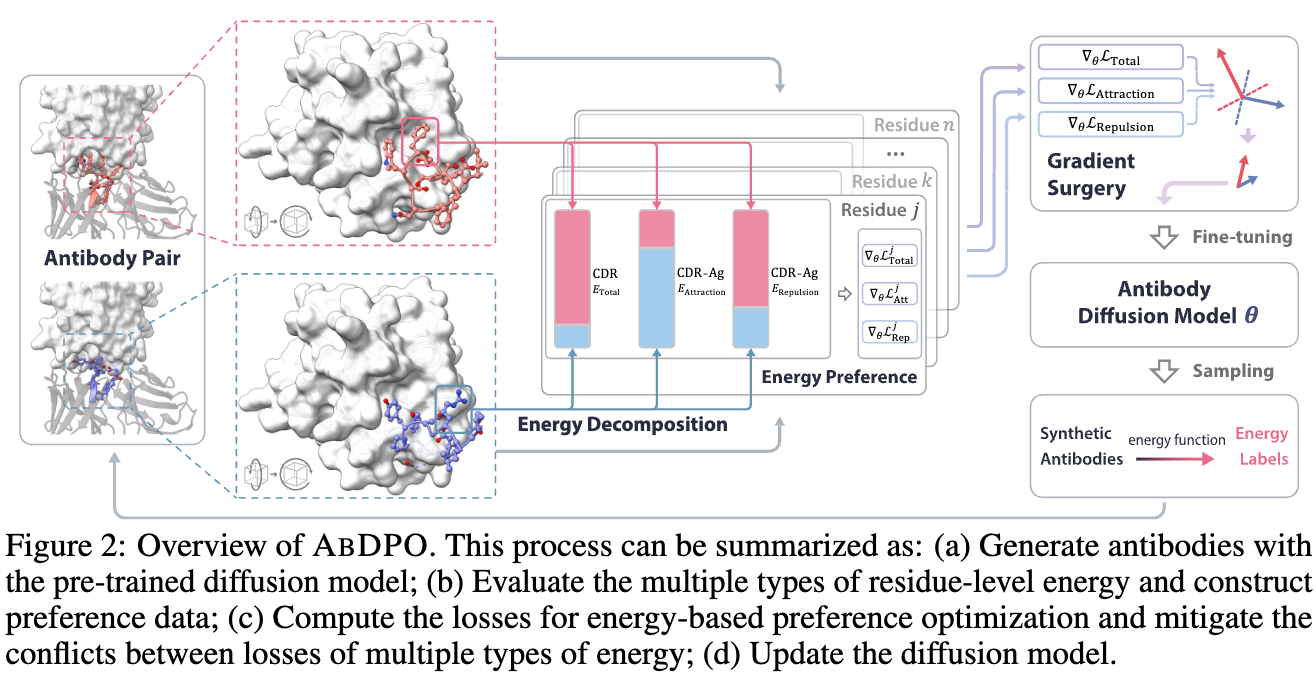
28.基于直接能量偏好优化的抗原特异性抗体设计
Antigen-Specific Antibody Design via Direct Energy-based Preference Optimization
论文作者:周相鑫,薛东雨,陈睿哲,郑在翔,王亮,顾全全
研究介绍:
抗体设计是一项在治疗学和生物学等多个领域具有重要意义的关键任务,由于其复杂性,面临着相当大的挑战。在本文中,我们将特异性抗原的抗体序列 - 结构协同设计作为一种优化问题,考虑其合理性和功能性。利用一个预训练的条件扩散模型,该模型通过等变神经网络联合建模抗体的序列和结构,我们提出了基于直接能量偏好优化的方法,指导生成既合理又对特定抗原具有显著结合亲和力的抗体。我们的方法涉及使用残基级别的分解能量偏好来微调预训练的扩散模型。此外,我们使用梯度修正技术来解决吸引力和排斥力等各种能量类型之间的冲突。在 RAbD 基准测试上的实验表明,我们的方法有效地优化了生成抗体的能量,并在设计具有低总能量和高结合亲和力的高质量抗体方面达到了最先进的性能,展示了我们方法的优越性。
29.Hallo3D:一种用于一致性3D内容生成的多模态幻觉检测与缓解方法
Hallo3D: Multi-Modal Hallucination Detection and Mitigation for Consistent 3D Content Generation
论文作者:王宏博,曹杰,刘进,周晓强,黄怀波(通讯),赫然
研究介绍:
近期,预训练的二维扩散模型显著提升了三维内容生成中的视觉先验指导能力。然而,该过程通常缺乏几何约束,导致空间感知和多视角不一致。为了解决这一问题,本工作引入了Hallo3D,一种无需额外数据支持的三维内容生成方法,利用大型多模态模型的几何感知能力来检测和减轻这些幻觉。本工作的方法遵循生成-检测-校正的范式,使用多模态不一致作为查询信息来指导幻觉的检测,并制定增强的负面提示,确保渲染的一致性。此外,本工作提出了一种去噪策略,通过注意力机制在视觉指导过程中维持多视角的一致性颜色和纹理。该方法与数据无关,易于与现有的三维内容生成框架集成,支持文本驱动和图像驱动的方式。大量实验表明,本工作的方法在显著改善生成的三维内容的一致性和质量方面表现出色,尤其是在减轻基于二维预训练模型常见的幻觉方面。
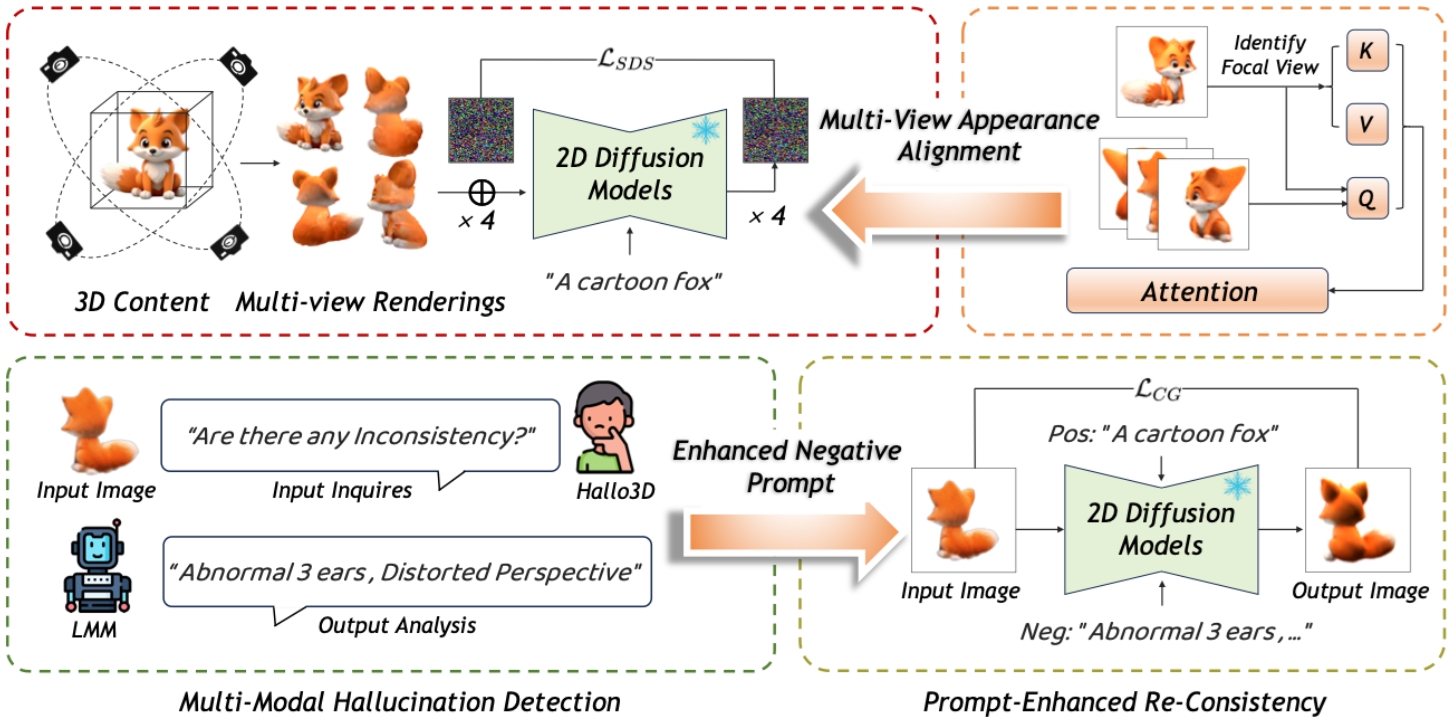
本工作的模型流程图
30.DreamClear: 使用隐私安全的数据集实现高性能的真实场景图像复原
DreamClear: High-Capacity Real-World Image Restoration with Privacy-Safe Dataset Curation
论文作者:艾雨昂,周晓强,黄怀波,韩笑天,陈政宇,尤全增,杨红霞
研究介绍:
由于现有模型容量不足和数据集不够全面,图像复原在真实场景中面临严峻挑战。本工作针对真实场景中的图像复原问题提出了两种创新策略:GenIR和DreamClear。
GenIR是一种创新的数据策展流程,旨在克服现有数据集规模小、泛化能力不足的问题。GenIR采用三阶段流程:图像-文本对构建、基于双重提示的微调,以及数据生成与过滤。这一方法避免了繁重的数据抓取过程,确保了版权合规,同时提供了一种成本效益高、隐私安全的解决方案,最终构建了包含一百万张高质量2K图像的大规模数据集。
DreamClear是一个基于Diffusion Transformer的图像复原模型。该模型利用文本-图像生成模型的生成先验和多模态大模型的感知能力,实现逼真的图像复原。为了增强模型对各种真实场景中退化情况的适应性,我们引入了自适应调制器混合模块,它通过token级别的退化先验,动态整合各种复原专家,从而扩展了模型可处理的退化范围。
实验结果表明,DreamClear表现卓越,验证了我们提出的双重策略在真实场景图像复原中的有效性。

图1. DreamClear的真实场景图像复原效果

图2 DreamClear整体结构
31.从模式补全中学习:自监督可控生成
Learning from Pattern Completion: Self-supervised Controllable Generation
论文作者:陈智强,范国藩,高金颖,马雷,雷博,黄铁军,余山
研究介绍:
人类大脑具有很强的自发联想能力,可以通过不同视觉属性联想到相同或相似的视觉场景,例如将草图或涂鸦与现实世界的视觉对象联系起来。受启发于可能有助于大脑联想能力的神经机制,特别是皮层模块化和海马体模式补全机制,我们提出了一个自监督可控生成(Self-supervised Controllable Generation, SCG)框架。首先,我们引入了一个等变约束,以促进自编码器模块间的独立性和模块内的相关性,从而实现功能分化。随后,基于这些专门的模块,我们采用了一种自监督的模式补全方法来进行可控生成训练。实验结果表明,所提出的模块化自动编码器有效地分化出了对颜色、亮度、边缘敏感的的功能模块,并自发涌现出包括朝向选择性、颜色拮抗、中心-周围感受野等类脑的特性。通过自监督模式补全,所提出的SCG自发涌现出联想生成能力,并能够很好地泛化到未训练的绘画、素描、远古壁画等联想生成任务上。与之前的代表性方法ControlNet相比,所提出的SCG不仅在更具挑战性的高噪声场景中表现出优异的鲁棒性,而且由于其自监督的方式,还具有更有前景的scaling-up潜力。
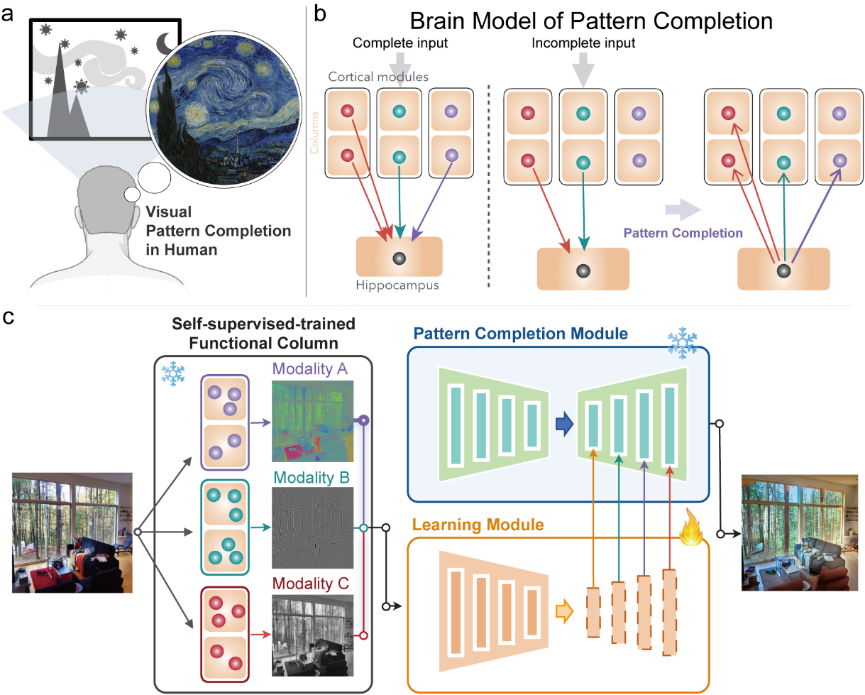
图1. SCG框架。SCG有两个组成部分:一个是通过我们设计的模块化等变约束,促进网络自发地特化出不同的功能模块;另一种是通过模式补全来执行自监督可控生成。

图2. 基于等变约束的模块化自编码器架构
32.基于脑记录的视觉重建与语言交互增强研究
Neuro-Vision to Language: Enhancing Brain Recording-based Visual Reconstruction and Language Interaction
论文作者:申国斌, 赵东城, 何翔, 冯令昊, 董一廷, 王纪航, 张倩, 曾毅
研究介绍:
解码非侵入性脑信号对于推动人类认知理解至关重要,但由于个体差异和神经信号表征的复杂性,因此面临诸多挑战。传统方法通常需要定制化模型和大量实验,且在视觉重建任务中缺乏可解释性。我们提出的框架利用Vision Transformer 3D,将三维大脑结构与视觉语义相结合,通过高效的统一特征提取器对fMRI特征与多层次视觉嵌入进行对齐,无需特定个体模型即可从单次试验数据中提取信息。该提取器整合了多层次视觉特征,简化了与大语言模型(LLMs)的整合。此外,我们通过多样的fMRI-图像相关文本数据增强了fMRI数据集,以支持多模态大模型的开发。与LLMs的结合提升了解码能力,完成了脑信号描述、复杂推理、概念定位及视觉重建等任务,精确地从脑信号中识别基于语言的概念,增强了可解释性。这一进展为非侵入式脑解码在神经科学和人机交互中的应用奠定了基础。

结合fMRI特征提取与大语言模型(LLMs)进行交互式沟通和重建的多模态集成框架概览。该架构包括: (a) 使用VAE和CLIP嵌入进行特征对齐的双流路径; (b) 一个3D fMRI预处理器 p 以及一个fMRI特征提取器; (c) 与fMRI集成的多模态LLMs。提取的特征随后输入LLMs,用于处理自然语言指令并生成响应或视觉重建。
33. 用于视觉语言目标检测的零样本可泛化增量学习
Zero-shot Generalizable Incremental Learning for Vision-Language Object Detection
论文作者:邓杰仁,张好剑,丁昆,胡建华,张兴轩,王云宽
研究介绍:
本文提出了增量视觉语言目标检测,这是一个新颖的学习任务,旨在增量地使预训练的视觉语言目标检测模型适应各种专业领域,同时保持其在广义领域的零样本泛化能力。为了应对这一新的挑战,本文提出了零干扰可重参化适应,这是一种引入零干扰损失和重参化技术的新方法,可以在不显著增加内存使用的情况下解决增量视觉语言目标检测问题。在COCO和ODinW-13数据集上的全面实验表明,零干扰可重参化适应有效地保障了视觉语言目标检测模型的零样本泛化能力,同时支持模型不断适应新任务。具体地,在ODinW-13数据集上进行训练后,零干扰可重参化适应的表现优于已有的增量目标检测方法CL-DETR和iDETR,分别将零样本泛化能力提高了13.91和8.74个AP。

图1.将视觉语言目标检测模型适应到多个下游任务的三种不同范式:零样本学习(Zero-shot), 一般增量学习(General IOD), 增量视觉语言目标检测(IVLOD)。

图2.零干扰可重参化适应方法
34.跨任务策略指导的高效多任务强化学习
Efficient Multi-Task Reinforcement Learning with Cross-Task Policy Guidance
论文作者:何金岷、李凯、臧一凡、傅浩波、付强、兴军亮、程健
研究介绍:
多任务强化学习旨在高效利用各任务间的共享信息,促进多任务的同时学习。现有方法主要侧重于通过精心设计的网络结构或定制的优化过程进行参数共享。然而,这些方法忽视了一种直接且互补的方式来利用任务间的相似性,即已经掌握某些技能的任务控制策略可以为未掌握的任务提供显式指导,加速学习该技能的应用。为此,我们提出了一个名为跨任务策略指导(Cross-Task Policy Guidance,CTPG)的新框架。其为每个任务训练一个指导策略,从所有任务控制策略中选择与环境交互的行为策略,从而生成更好的训练轨迹。此外,我们提出了两种门控机制来提高学习效率:其一过滤掉对指导无益的控制策略,其二则阻止不需要被指导的任务。CTPG是一个通用框架,可以与现有的参数共享方法适配,实验证明将CTPG与这些方法结合,能够显著提升在操作和运动基准测试环境中的性能。

图1.机械臂控制任务间存在的全部或局部策略共享

图2.CTPG框架示意图
35.基于上下文搜索的对手建模
Opponent Modeling with In-context Search
论文作者:
景煜恒,刘秉运,李凯,臧一凡,傅浩波,付强,兴军亮,程健
研究介绍:
对手建模是一个长期存在的研究领域,旨在通过建模多智能体环境中关于对手的信息来提升决策能力。然而,现有方法通常面临难以对未知对手策略进行泛化以及表现不稳定等挑战。为了解决这些问题,我们提出了一种基于上下文学习和决策时搜索的新方法,称为基于上下文搜索的对手建模(Opponent Modeling with In-context Search, OMIS)。OMIS利用基于上下文学习的预训练来训练一个用于决策的Transformer模型。它包含三个基于上下文的模块:学习对手策略的最佳响应的执行者、模仿对手行为的对手模仿者以及评估状态价值的评论者。在测试中,面对具有未知非平稳策略的对手时,OMIS使用预训练的上下文模块进行决策时搜索,以优化执行者的策略。在理论上,我们证明了在合理假设下,OMIS无需搜索即可在对手策略识别中收敛,并具备良好的泛化能力;而结合搜索后,OMIS具有性能提升的保证,表现更加稳定。在竞争、合作及混合环境中,OMIS在适应对手策略方面表现出了比其他对手建模方法更为有效和稳定的性能。

图1.左图:OMIS的预训练过程和神经架构。预训练步骤如下:
(1)针对训练对手策略集合 中所有策略训练最佳响应策略(BRs)。(2)从
中所有策略训练最佳响应策略(BRs)。(2)从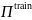 中不断采样对手策略,并使用其BR与其对战以收集训练数据。(3)使用基于ICL(上下文学习)的监督学习预训练一个Transformer模型,该模型包含三个组件:一个执行者
中不断采样对手策略,并使用其BR与其对战以收集训练数据。(3)使用基于ICL(上下文学习)的监督学习预训练一个Transformer模型,该模型包含三个组件:一个执行者 ,一个对手模仿者
,一个对手模仿者 ,以及一个评论者
,以及一个评论者 。
。
右图:OMIS的测试过程。在测试中,OMIS通过在每个时间步进行决策时搜索来提升 。搜索步骤如下:(1)针对每个合法动作执行多次
。搜索步骤如下:(1)针对每个合法动作执行多次 步rollout,其中
步rollout,其中 和
和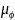 分别用于模拟我方智能体和对手的动作。
分别用于模拟我方智能体和对手的动作。 用于估计终止搜索状态的价值。(2)估计所有合法动作在搜索下的动作价值
用于估计终止搜索状态的价值。(2)估计所有合法动作在搜索下的动作价值 ,搜索策略
,搜索策略 选择具有最大
选择具有最大 值的合法动作。(3)使用混合技术在
值的合法动作。(3)使用混合技术在 和
和 之间进行权衡,以选择实际要执行的动作。
之间进行权衡,以选择实际要执行的动作。
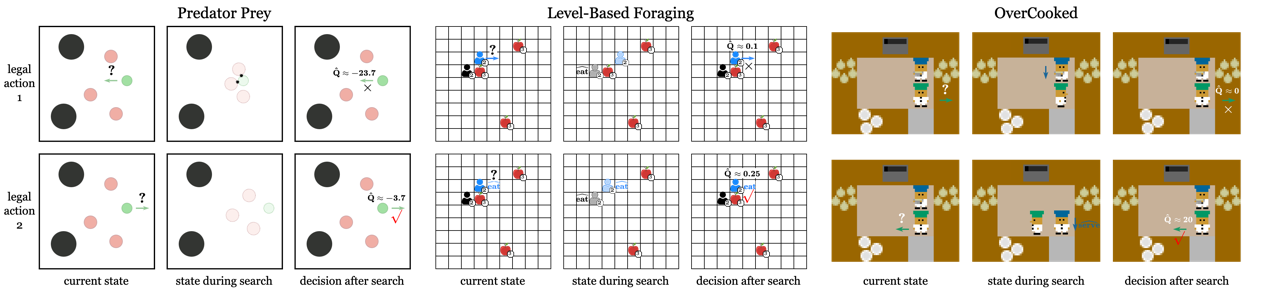
图2在与使用未知策略的对手对战时,OMIS的搜索能够迅速评估每个合法动作,预测对手在搜索过程中的行动,并最终选择最有利的动作。OMIS表现出一些有趣的现象:在Predator Prey环境中,搜索使得我方智能体(绿色)能够避开使用包围策略的对手(红色)的围捕;在Level-Based Foraging环境中,搜索使得我方智能体(蓝色)能够与对手(黑色)合作,采食比自己等级更高的苹果;在OverCooked环境中,搜索帮助我方智能体(绿色)避免阻挡合作伙伴(蓝色)的通路,从而使其能够顺利上菜。