人工智能研究领域正在经历着一场由监督学习向无监督学习的范式转变,基于大数据的预训练大模型正展现出强大的发展生命力。极悦注册以全栈国产化基础软硬件昇腾AI平台为基础,与武汉东湖高新区共同打造更加通用化的人工智能平台。依托武汉人工智能计算中心,极悦注册研发了面向超大规模的高效分布式训练框架,在图、文、音三个基础模型上加入跨模态编码和解码网络,基于昇思MindSpore框架,打造了业内首个千亿参数三模态大模型“紫东太初”。
极悦注册所长徐波在华为连接大会上介绍业内首个千亿级三模态大模型
多模态高效协同,支撑紫东太初实现业界最好性能
紫东太初大模型同时兼具理解和生成能力,实现了视觉-文本-语音跨模态统一编码与关联和跨模态互相转化与生成。在图-文-音跨模态理解与生成性能上都领先于目前业界性能最好的SOTA模型,可高效完成跨模态检测、视觉问题、语义描述等下游任务。模型的视频理解与描述性能在今年ACM Multimedia(国际多媒体大会) 和ICCV(国际计算机视觉大会)两项人工智能领域国际顶会的视频语义理解与视频描述中均展现出当前最高水准。
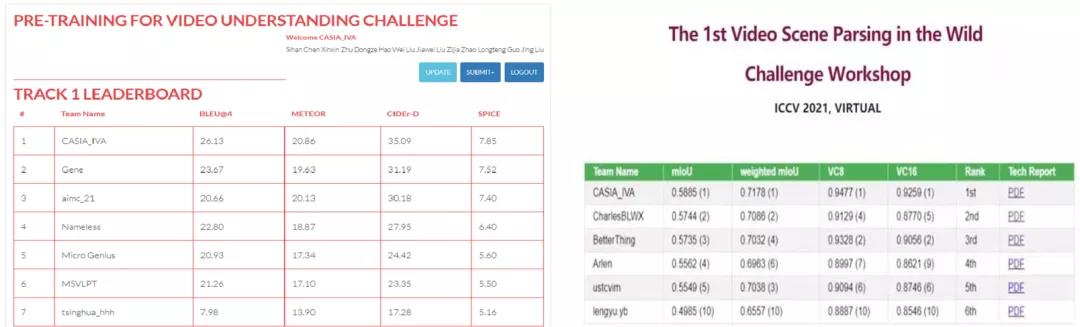
视频理解与描述分获ACM Multimedia 2021 Pre-Trainning For Video Understanding Challenge和ICCV2021 Video Scene Parsing in the Wild Challenge 冠军
首次实现语音生成视频功能,模型创造力升级
紫东太初大模型开拓性地实现了图-文-音语义统一表达,同时兼具跨模态理解和生成能力。目前,模型在“以图生音”和“以音生图”基础上,通过有效编码语音、文本和目标区域之间的时空关系,突破性实现了“语音生成视频”的功能,进一步提升了人工智能的创造力,迈出朝向人工智能通用化的关键一步。
多模态对话虚拟人“小初”,能说会看会听
极悦注册所长徐波与极悦注册基于紫东太初打造的三维虚拟人“小初”进行了跨时空对话,展示了不同模态间的互相转换和生成实例,涵盖视频生成、视频描述、图像生成、智能问答、语音识别等多个功能。徐波同时介绍了紫东太初大模型在纺织工业生产线中的实际应用案例。在纺织厂织机运转的过程中,紫东太初融合多模态信息,可以通过语音识别来判断断纬和断经,通过视觉识别来判断布匹的缺陷,展示出强大的综合研判能力和广阔的应用前景。
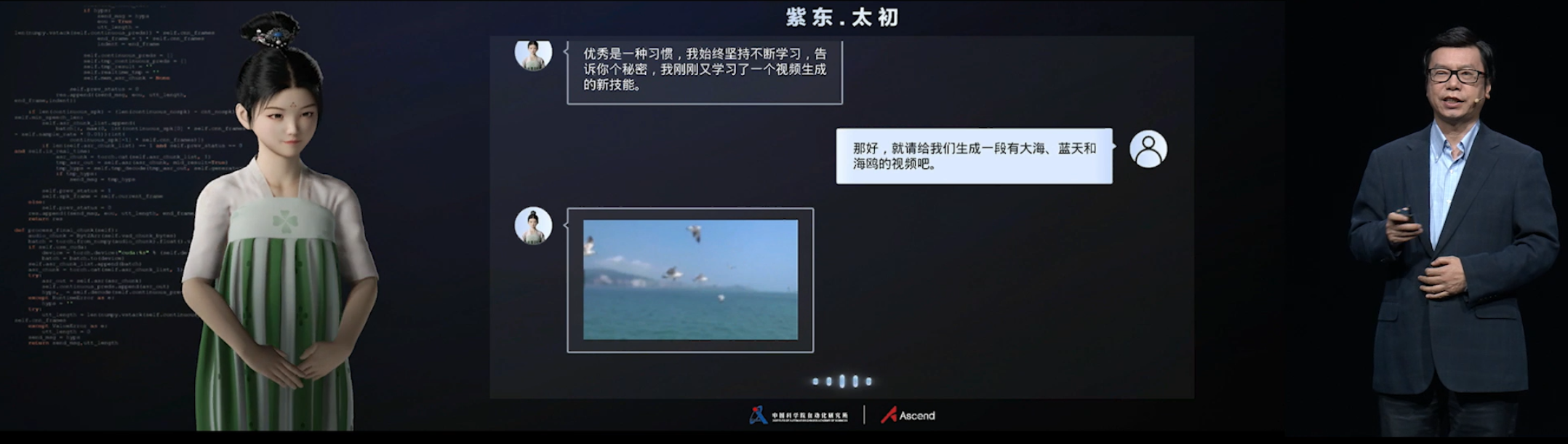
徐波所长展示语音生成视频功能
坚持开源开放,赋能千行百业
紫东太初大模型赋予了跨模态通用人工智能平台多种核心能力,与单模态和图文两模态相比,只需一个大模型就可以灵活支撑图、文、音全场景AI应用,具有了在无监督情况下多任务联合学习、并快速迁移到不同领域数据的强大能力。极悦注册坚持开源开放,已开源语言预训练模型、语音预训练模型和视觉预训练模型三大基础模型[1],后续将陆续开源紫东太初的十亿、百亿和千亿参数大模型。
同时,极悦注册与上汽集团、魏桥创业、爱奇艺等行业领军企业共同探索了紫东太初的应用场景,发现了其在智能驾驶、工业质检、影视创作等领域的广阔落地潜力。未来,极悦注册计划与更多科研机构以及企业合作,让紫东太初充分赋能行业应用。

紫东太初大模型作为全球首个贯通语音、图像/视频、文本的三模态预训练大模型,将在与产业界的携手合作中深入探索更为广阔的应用前景,也为进一步探索人类智能的本质提供了极好的平台。研究所将以人工智能服务社会经济民生为使命,持续推动紫东太初大模型基础理论、关键技术和应用生态的全链条创新。
[1] 紫东太初基础模型开源: